本文主要想说说 iOS 的性能问题的原因,如何监控发现问题,以及如何预防和解决这些问题。
为啥要说是二刷呢,因为以前我也写过好几篇性能相关的文章。有性能优化的深入剖析 iOS 性能优化,包体积相关的GMTC 上分享滴滴出行 iOS 端瘦身实践的 Slides、用 Swift 编写的工程代码静态分析命令行工具 smck、使用Swift3开发了个macOS的程序可以检测出objc项目中无用方法,然后一键全部清理、使用 LLVM、使用 LLVM 分享的幻灯片。还有启动速度相关的App 启动提速实践和一些想法和如何对 iOS 启动阶段耗时进行分析。编译相关的深入剖析 iOS 编译 Clang / LLVM
这次我尽量绕开以前谈的,只简单提提,着重说些以前没提或者说的少的。来个互补吧。也加了些前段时间去深圳给平安做分享的内容。
这次内容也整理进了小册子方便下载后按目录日常查阅,小册子程序本身也是开源的,欢迎 Clone 查看。
由于 iOS 性能问题涉及面很多,我先做个分类,这样好一个一个的说。大概顺序是会先从造成用户体验损失最大的卡顿、内存爆掉来开头,然后说下启动和安装包体积怎么优化,说说性能分析的工具和方案,最后讲讲怎么使用 Bazel 提速编译。
卡顿
先了解下 iOS 视图和图像的显示原理。
介绍
我们了解的 UIKit 和 SwiftUI 都是提供了高层次的管理界面元素的 API。另外还有 ImageView 是专门用来显示图像的类。底层是 Core Graphics,也可以叫做 Quartz,这是 iOS 的 2D 绘图引擎,直接和硬件交互。Core Animation 是处理动画和图像渲染的框架,将图层内容提交到屏幕,并处理图层之间的动画。
底层图形渲染管线 iOS 用的是 Metal。Core Animation 会将要渲染的图层内容转换成 GPU 可以理解的命令,然后让 Metal 渲染到屏幕上。
大图
最容易造成掉帧的原因就是大图。由于大图数据量较大,对应渲染指令就比较多,会影响渲染的时间,造成卡顿。可以在显示大图前,先加载并显示较小尺寸的缩略图,等用户确实需要查看高清版本时,再加载完整图片。
举个例子:
import SwiftUI
struct ThumbnailImageView: View {
let thumbnailImage: UIImage
let fullSizeImageURL: URL
@State private var fullSizeImage: UIImage? = nil
var body: some View {
ZStack {
if let fullSizeImage = fullSizeImage {
Image(uiImage: fullSizeImage)
.resizable()
.scaledToFit()
} else {
Image(uiImage: thumbnailImage)
.resizable()
.scaledToFit()
.onAppear(perform: loadFullSizeImage)
}
}
}
private func loadFullSizeImage() {
DispatchQueue.global().async {
if let data = try? Data(contentsOf: fullSizeImageURL),
let image = UIImage(data: data) {
DispatchQueue.main.async {
self.fullSizeImage = image
}
}
}
}
}在加载大图时使用 CGImageSource 逐步解码图片,在低分辨率时减少内存占用。
import UIKit
func loadImageWithLowMemoryUsage(url: URL) -> UIImage? {
guard let source = CGImageSourceCreateWithURL(url as CFURL, nil) else {
return nil
}
let options: [NSString: Any] = [
kCGImageSourceShouldCache: false, // 避免直接缓存到内存
kCGImageSourceShouldAllowFloat: true
]
return CGImageSourceCreateImageAtIndex(source, 0, options as CFDictionary).flatMap {
UIImage(cgImage: $0)
}
}异步绘制
系统资源方面,CPU 主要是计算视图层次结构,布局、文本的绘制、图像解码以及 Core Graphics 绘制。GPU 是处理图层合并、图像渲染、动画和 Metal 绘制。CPU 负责准备数据,GPU 负责渲染这些数据。
因此,CPU 方面需要注意过多的子视图会让 CPU 很累,需要简化视图层次。setNeedsDisplay 或 layoutSubviews 也不易过多调用,这样会让重新绘制不断发生。图像解码也不要放主线程。GPU 方面就是图片不要过大,主要是要合适,保持图片在一定分辨率下清晰就好,另外就是可以采用上面提到的大图优化方式让界面更流畅。
UIView 是界面元素的基础,用于响应用户输入,绘制流程是当视图内容或大小变化时会调用 setNeedsDisplay 或 setNeedsLayout 标记为要更新状态,下个循环会调用 drawRect: 进行绘制。绘制是 Core Graphics,也就是 CPU,显示靠的是 Core Animation,用的是 GPU。异步绘制就是将 Core Graphics 的动作放到主线程外,这样主线程就不会收到绘制计算量的影响。
Core Graphics 的异步绘制是使用 UIGraphicsBeginImageContextWithOptions 函数在后台线程中创建一个 CGContext。使用 GCD 或 NSOperationQueue 来在后台线程中进行绘制操作。完成绘制后,将结果返回主线程以更新 UI。
下面是一个异步绘制的示例代码:
import UIKit
class AsyncDrawingView: UIView {
private var asyncImage: UIImage?
override func draw(_ rect: CGRect) {
super.draw(rect)
// 如果有异步绘制的图片,直接绘制它
asyncImage?.draw(in: rect)
}
func drawAsync() {
Task {
// 创建图形上下文
let size = self.bounds.size
UIGraphicsBeginImageContextWithOptions(size, false, 0.0)
guard let context = UIGraphicsGetCurrentContext() else { return }
// 进行绘制操作
context.setFillColor(UIColor.blue.cgColor)
context.fill(CGRect(x: 0, y: 0, width: size.width, height: size.height))
// 获取绘制结果
let image = UIGraphicsGetImageFromCurrentImageContext()
UIGraphicsEndImageContext()
// 更新 UI,回到主线程
await MainActor.run {
self.asyncImage = image
self.setNeedsDisplay() // 触发 draw(_:) 方法重新绘制
}
}
}
}对于复杂的异步绘制,特别是涉及 UIView 的情况下,可以考虑这两个方法。首先是自定义 CALayer 并实现其 draw(in:) 方法来进行异步绘制。其次是使用 UIView 的 draw(:) 方法,在子类中重写 draw(:) 方法,并结合异步操作来更新绘制内容。
import UIKit
class AsyncDrawingLayer: CALayer {
override func draw(in ctx: CGContext) {
super.draw(in: ctx)
Task {
// 在子线程中执行绘制操作
await withCheckedContinuation { continuation in
Task.detached {
// 执行绘制操作
ctx.setFillColor(UIColor.red.cgColor)
ctx.fill(self.bounds)
// 完成绘制操作后继续
continuation.resume()
}
}
// 回到主线程更新 UI
await MainActor.run {
self.setNeedsDisplay() // 触发 draw(in:) 重新绘制
}
}
}
}离屏渲染也容易掉帧,应该尽量的避免复杂的圆角、阴影效果,或者使用更简单的图形操作。如可能,减少对 layer 的属性设置,尤其是那些可能引起离屏渲染的属性。
运算转移到 GPU
CPU主要负责用户交互的处理,如果能够将运算转移到 GPU 上,就可以给 CPU 减压了。
以下是一些常见的方法和技术,可以在iOS中将计算任务从CPU转移到GPU:
通过Metal的计算管线(Compute Pipeline),可以编写计算着色器(Compute Shaders)在GPU上执行大量并行计算任务,如物理模拟、数据分析等。
// 使用Metal进行简单的计算操作
let device = MTLCreateSystemDefaultDevice()
let commandQueue = device?.makeCommandQueue()
let shaderLibrary = device?.makeDefaultLibrary()
let computeFunction = shaderLibrary?.makeFunction(name: "computeShader")
let computePipelineState = try? device?.makeComputePipelineState(function: computeFunction!)Core Image 是一个强大的图像处理框架,内置了许多优化的滤镜(Filters),并能够自动将图像处理任务分配到GPU上执行。
let ciImage = CIImage(image: inputImage)
let filter = CIFilter(name: "CISepiaTone")
filter?.setValue(ciImage, forKey: kCIInputImageKey)
filter?.setValue(0.8, forKey: kCIInputIntensityKey)
let outputImage = filter?.outputImageCore Animation 是iOS的高效动画框架,它会将大部分动画的执行过程自动转移到GPU上。这包括视图的平移、缩放、旋转、淡入淡出等基本动画效果。通过使用CALayer和各种动画属性(如position、transform等),你可以创建平滑的动画,这些动画将在GPU上硬件加速执行。
let layer = CALayer()
layer.position = CGPoint(x: 100, y: 100)
let animation = CABasicAnimation(keyPath: "position")
animation.toValue = CGPoint(x: 200, y: 200)
animation.duration = 1.0
layer.add(animation, forKey: "positionAnimation")SpriteKit 和 SceneKit 是两个高层次的框架,分别用于2D和3D游戏开发。它们内部利用GPU进行图形渲染和物理模拟,极大地减少了CPU的负担。
let scene = SKScene(size: CGSize(width: 1024, height: 768))
let spriteNode = SKSpriteNode(imageNamed: "Spaceship")
spriteNode.position = CGPoint(x: scene.size.width/2, y: scene.size.height/2)
scene.addChild(spriteNode)线程死锁
线程操作稍不留神就会让主线程卡死,比如dispatch_once中同步访问主线程导致的死锁。子线程占用锁资源导致主线程卡死。dyld lock、selector lock和OC runtime lock互相等待。
同步原语(synchronization primitive)会阻塞读写任务执行。iOS 中常用的会阻塞读写任务执行的同步原语有 NSLock、NSRecursiveLock、NSCondition、NSConditionLock、信号量(Dispatch Semaphore)、屏障(Dispatch Barrier)、读写锁(pthread_rwlock_t)、互斥锁(pthread_mutex_t)、@synchronized 指令、os_unfair_lock、原子性属性(Atomic Properties)、NSOperationQueue 和 操作依赖(Dependencies)、Actors。
这些同步原语各有优缺点,选择合适的同步机制取决于具体的应用场景。例如,pthread_rwlock_t适用于读多写少的情况,而NSLock或@synchronized则适用于简单的互斥需求。GCD的信号量和屏障则提供了更高层次的并发控制手段。因此在使用同步原语时要特别注意了。检测卡死情况也要重点从同步原语来入手。
IO 过密
磁盘操作通常是阻塞性的,可以将磁盘 IO 操作放到后台线程中执行。
import SwiftUI
struct ContentView: View {
@State private var data: String = "Loading..." // `data` 用于存储从磁盘读取的数据,并在 UI 中显示。
var body: some View {
VStack {
Text(data)
.padding()
Button("Load Data") {
loadData()
}
}
}
func loadData() {
// 通过 `Task` 创建一个并发上下文来运行异步代码块。在这个代码块中执行耗时的磁盘 IO 操作。
Task {
// 在后台执行磁盘 IO 操作
let loadedData = await performDiskIO()
// 在主线程更新 UI
await MainActor.run {
data = loadedData
}
}
}
// 模拟一个磁盘 IO 操作,可能是从文件中读取大数据
func performDiskIO() async -> String {
// 模拟磁盘操作耗时
try? await Task.sleep(nanoseconds: 2_000_000_000) // 2 seconds delay
// 这里可以进行实际的磁盘读取操作
// 例如读取文件内容:
// let fileURL = ...
// let data = try? String(contentsOf: fileURL)
return "Data Loaded Successfully!"
}
}
@main
struct DiskIOApp: App {
var body: some Scene {
WindowGroup {
ContentView()
}
}
}跨进程通信导致卡顿
进程间通信(IPC)是一种重要的机制,它允许不同的进程或应用程序之间交换信息。然而,某些系统API的调用可能会导致卡顿或性能问题,特别是在以下几种情况下:
- CNCopyCurrentNetworkInfo 获取 WiFi 信息
- 设置系统钥匙串 (Keychain) 中的值
- NSUserDefaults 调用写操作
- CLLocationManager 获取当前位置权限状态
- UIPasteboard 设置和获取值
- UIApplication 通过 openURL 打开其他应用
在执行以上操作时,心理上是要有预期的。能有替代方案的话那是最好的了。
卡顿监控
监控原理是注册runloop观察者,检测耗时,记录调用栈,上报后台分析。长时间卡顿后,若未进入下一个活跃状态,则标记为卡死崩溃上报。
以下是一个 iOS 卡死监控的代码示例:
#import <Foundation/Foundation.h>
#import <UIKit/UIKit.h>
#import <execinfo.h>
#import <sys/time.h>
// 定义 Runloop 模式的枚举
typedef enum {
eRunloopDefaultMode, // 默认模式
eRunloopTrackingMode // 追踪模式
} RunloopMode;
// 全局变量,用于记录 Runloop 的活动状态和模式
static CFRunLoopActivity g_runLoopActivity;
static RunloopMode g_runLoopMode;
static BOOL g_bRun = NO; // 标记 Runloop 是否在运行
static struct timeval g_tvRun; // 记录 Runloop 开始运行的时间
// HangMonitor 类,用于监控卡死情况
@interface HangMonitor : NSObject
@property (nonatomic, assign) CFRunLoopObserverRef runLoopBeginObserver; // Runloop 开始观察者
@property (nonatomic, assign) CFRunLoopObserverRef runLoopEndObserver; // Runloop 结束观察者
@property (nonatomic, strong) dispatch_semaphore_t semaphore; // 信号量,用于同步
@property (nonatomic, assign) NSTimeInterval timeoutInterval; // 超时时间
- (void)addRunLoopObserver; // 添加 Runloop 观察者的方法
- (void)startMonitor; // 启动监控的方法
- (void)logStackTrace; // 记录调用栈的方法
- (void)reportHang; // 上报卡死的方法
@end
@implementation HangMonitor
// 单例模式,确保 HangMonitor 只有一个实例
+ (instancetype)sharedInstance {
static HangMonitor *instance;
static dispatch_once_t onceToken;
dispatch_once(&onceToken, ^{
instance = [[HangMonitor alloc] init];
});
return instance;
}
// 初始化方法
- (instancetype)init {
self = [super init];
if (self) {
_timeoutInterval = 6.0; // 设置超时时间为6秒
_semaphore = dispatch_semaphore_create(0); // 创建信号量
[self addRunLoopObserver]; // 添加 Runloop 观察者
[self startMonitor]; // 启动监控
}
return self;
}
// 添加 Runloop 观察者的方法
- (void)addRunLoopObserver {
NSRunLoop *curRunLoop = [NSRunLoop currentRunLoop]; // 获取当前 Runloop
// 创建第一个观察者,监控 Runloop 是否处于运行状态
CFRunLoopObserverContext context = {0, (__bridge void *) self, NULL, NULL, NULL};
CFRunLoopObserverRef beginObserver = CFRunLoopObserverCreate(kCFAllocatorDefault, kCFRunLoopAllActivities, YES, LONG_MIN, &myRunLoopBeginCallback, &context);
CFRetain(beginObserver); // 保留观察者,防止被释放
self.runLoopBeginObserver = beginObserver;
// 创建第二个观察者,监控 Runloop 是否处于睡眠状态
CFRunLoopObserverRef endObserver = CFRunLoopObserverCreate(kCFAllocatorDefault, kCFRunLoopAllActivities, YES, LONG_MAX, &myRunLoopEndCallback, &context);
CFRetain(endObserver); // 保留观察者,防止被释放
self.runLoopEndObserver = endObserver;
// 将观察者添加到当前 Runloop 中
CFRunLoopRef runloop = [curRunLoop getCFRunLoop];
CFRunLoopAddObserver(runloop, beginObserver, kCFRunLoopCommonModes);
CFRunLoopAddObserver(runloop, endObserver, kCFRunLoopCommonModes);
}
// 第一个观察者的回调函数,监控 Runloop 是否处于运行状态
void myRunLoopBeginCallback(CFRunLoopObserverRef observer, CFRunLoopActivity activity, void *info) {
HangMonitor *monitor = (__bridge HangMonitor *)info;
g_runLoopActivity = activity; // 更新全局变量,记录当前的 Runloop 活动状态
g_runLoopMode = eRunloopDefaultMode; // 更新全局变量,记录当前的 Runloop 模式
switch (activity) {
case kCFRunLoopEntry:
g_bRun = YES; // 标记 Runloop 进入运行状态
break;
case kCFRunLoopBeforeTimers:
case kCFRunLoopBeforeSources:
case kCFRunLoopAfterWaiting:
if (g_bRun == NO) {
gettimeofday(&g_tvRun, NULL); // 记录 Runloop 开始运行的时间
}
g_bRun = YES; // 标记 Runloop 处于运行状态
break;
case kCFRunLoopAllActivities:
break;
default:
break;
}
dispatch_semaphore_signal(monitor.semaphore); // 发送信号量
}
// 第二个观察者的回调函数,监控 Runloop 是否处于睡眠状态
void myRunLoopEndCallback(CFRunLoopObserverRef observer, CFRunLoopActivity activity, void *info) {
HangMonitor *monitor = (__bridge HangMonitor *)info;
g_runLoopActivity = activity; // 更新全局变量,记录当前的 Runloop 活动状态
g_runLoopMode = eRunloopDefaultMode; // 更新全局变量,记录当前的 Runloop 模式
switch (activity) {
case kCFRunLoopBeforeWaiting:
gettimeofday(&g_tvRun, NULL); // 记录 Runloop 进入睡眠状态的时间
g_bRun = NO; // 标记 Runloop 进入睡眠状态
break;
case kCFRunLoopExit:
g_bRun = NO; // 标记 Runloop 退出运行状态
break;
case kCFRunLoopAllActivities:
break;
default:
break;
}
dispatch_semaphore_signal(monitor.semaphore); // 发送信号量
}
// 启动监控的方法
- (void)startMonitor {
dispatch_async(dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_HIGH, 0), ^{
while (YES) {
long result = dispatch_semaphore_wait(self.semaphore, dispatch_time(DISPATCH_TIME_NOW, self.timeoutInterval * NSEC_PER_SEC));
if (result != 0) {
if (g_runLoopActivity == kCFRunLoopBeforeSources || g_runLoopActivity == kCFRunLoopAfterWaiting) {
[self logStackTrace]; // 记录调用栈
[self reportHang]; // 上报卡死
}
}
}
});
}
// 记录调用栈的方法
- (void)logStackTrace {
void *callstack[128];
int frames = backtrace(callstack, 128);
char **strs = backtrace_symbols(callstack, frames);
NSMutableString *stackTrace = [NSMutableString stringWithString:@"\n"];
for (int i = 0; i < frames; i++) {
[stackTrace appendFormat:@"%s\n", strs[i]];
}
free(strs);
NSLog(@"%@", stackTrace);
}
// 上报卡死的方法
- (void)reportHang {
// 在这里实现上报后台分析的逻辑
NSLog(@"检测到卡死崩溃,进行上报");
}
@end
// 主函数,程序入口
int main(int argc, char * argv[]) {
@autoreleasepool {
HangMonitor *monitor = [HangMonitor sharedInstance]; // 获取 HangMonitor 单例
return UIApplicationMain(argc, argv, nil, NSStringFromClass([AppDelegate class])); // 启动应用程序
}
}
以上代码中 HangMonitor 类会在主线程的 RunLoop 活动中检测是否有长时间的卡顿,并在检测到卡顿时记录调用栈并上报后台进行分析。超时时间设定为 6 秒,以覆盖大部分用户感知场景并减少性能损耗。
内存
引用计数
iOS 中用引用计数(ARC)来管理对象的生命周期。在ARC之前,开发者需要手动管理对象的内存,通过retain、release、autorelease等方法来控制对象的生命周期。SideTables 是一个包含8个 SideTable 的哈希数组,用于存储对象的引用计数和弱引用信息。每个 SideTable 对应多个对象。SideTable 包含三个主要成员:自旋锁(spinlock_t)、引用计数表(RefcountMap)、弱引用表(weak_table_t)。自旋锁用于防止多线程访问冲突,引用计数表存储对象的引用计数,弱引用表存储对象的弱引用信息。weak_table_t 是一个存储弱引用信息的哈希表,其元素是 weak_entry_t 类型。weak_entry_t 存储了弱引用该对象的指针的指针,即objc_object new_referrer。当对象被销毁时,weak引用的指针会被自动置为nil,防止野指针的出现。
当两个类互相持有对方的强引用时,会导致循环引用问题,导致内存无法正确释放,这会造成内存不断的增多。这类问题通常发生在闭包与类实例之间。为了打破这种循环引用,可以在闭包中使用捕获列表(capture list)将闭包中的引用声明为弱引用或无主引用。
import SwiftUI
class Element {
let title: String
let description: String?
lazy var convertToWeb: () -> String = { [unowned self] in
if let description = self.description {
return "<div class='line'><h2>\(self.title)</h2><p>\(description)</p></div>"
} else {
return "<div class='line'><h2>\(self.title)</h2></div>"
}
}
init(title: String, description: String? = nil) {
self.title = title
self.description = description
}
deinit {
print("\(title) is being deinitialized")
}
}
struct ContentView: View {
@State private var elm: Element? = Element(title: "Inception", description: "A mind-bending thriller by Christopher Nolan.")
var body: some View {
VStack {
if let html = elm?.convertToWeb() {
Text(html)
.padding()
.background(Color.yellow)
.cornerRadius(10)
}
Button("Clear") {
elm = nil
}
.padding()
.background(Color.red)
.foregroundColor(.white)
.cornerRadius(10)
}
.padding()
}
}在这个示例中,convertToWeb 是一个闭包,使用了 [unowned self] 捕获列表,以避免闭包与 Element 实例之间的强引用循环。
Swift 通常通过引用计数和内存自动管理来保证内存安全,然而在某些高性能或特定底层操作中,开发者可能需要直接操作内存。这时就需要使用到 Swift 的 Unsafe 系列指针类型,例如 UnsafeMutablePointer 和 UnsafePointer。UnsafePointer 是一个指向某种类型的指针,它允许只读访问内存地址上的数据。这意味着你可以读取该地址的数据但不能修改它。相反,UnsafeMutablePointer 允许你修改指针指向的内存区域内的数据。使用 UnsafeMutablePointer 修改内存时,必须确保内存已经正确地分配且不会被其他代码同时访问。否则,可能会导致程序崩溃或出现难以调试的问题。Swift 提供的一些辅助工具 withUnsafePointer(to:_:) 和 withUnsafeMutablePointer(to:_:),它们可以在有限的范围内确保内存操作的安全性。这些函数的使用可以帮助开发者避免一些常见的错误,确保指针的生命周期和作用域受到控制。
OOM
内存泄漏,难以监控。内存泄漏是指程序在运行过程中,由于设计错误或者代码实现不当,导致程序未能释放已经不再使用的内存,从而造成系统内存的浪费,严重的会导致程序崩溃。内存泄漏是一个非常严重的问题,因为它会导致程序运行速度变慢,甚至会导致程序崩溃。因此,我们在开发过程中,一定要注意内存泄漏的问题。
OOM(Out Of Memory)指的是iOS设备上应用因内存占用过高被系统强制终止的现象。iOS通过Jetsam机制管理内存资源,当设备内存紧张时,会终止优先级低或内存占用大的进程。分为FOOM(前台OOM)和BOOM(后台OOM),FOOM对用户体验影响更大。
Jetsam日志
包括pageSize(内存页大小)、states(应用状态)、rpages(占用的内存页数)、reason(终止原因)。通过pageSize和rpages可计算出应用崩溃时占用的内存大小。
在现代操作系统中,内存管理是一项关键任务。随着移动设备和桌面系统的复杂性增加,内存资源的高效使用变得更加重要。iOS和macOS通过引入“内存压力”(Memory Pressure)机制来优化内存管理,取代了传统的基于虚拟内存分页的管理方法。
虚拟内存系统允许操作系统将物理内存(RAM)和磁盘存储结合使用,以便在内存不足时将不常用的数据移至磁盘。分页(paging)是虚拟内存管理中的一种技术,它将内存划分为小块(页面),并根据需要将它们从物理内存交换到磁盘。然而,分页存在性能瓶颈,尤其是在存储访问速度远低于内存的情况下。
随着设备硬件的变化和用户体验要求的提高,苹果公司在iOS和macOS中引入了“内存压力”机制。内存压力是一种动态监测内存使用情况的技术,它能够实时评估系统内存的使用状态,并根据不同的压力级别采取相应的措施。
内存压力机制通过系统级别的反馈来管理内存。系统会监测内存的使用情况,并将压力分为四个级别:无压力(No Pressure)、轻度压力(Moderate Pressure)、重度压力(Critical Pressure)和紧急压力(Jetsam)。
压力级别的定义与响应:
- 无压力(No Pressure):系统内存充足,没有特别的内存管理措施。
- 轻度压力(Moderate Pressure):系统内存开始紧张,操作系统会建议应用程序释放缓存或非必要的资源。
- 重度压力(Critical Pressure):系统内存非常紧张,操作系统可能会暂停后台任务或终止不活跃的应用程序。
- 紧急压力(Jetsam):这是最严重的内存压力状态,系统可能会直接强制关闭占用大量内存的应用程序,以释放资源确保系统的稳定性。
系统对内存压力的应对措施
为了应对不同的内存压力,iOS和macOS系统采取了多种策略,包括:
- 缓存管理:系统会首先清除可丢弃的缓存数据,以减轻内存负担。
- 后台任务管理:在压力增加时,操作系统会优先暂停或终止低优先级的后台任务。
- 应用程序终止:在紧急情况下,系统会选择性地关闭那些占用大量内存且当前不活跃的应用程序,这一过程被称为“Jetsam”。
使用系统提供的工具(如vm_stat、memory_pressure等)监测应用程序的内存使用情况。这些工具可以帮助开发者识别内存泄漏、过度的缓存使用等问题。开发者可以通过这些机制感知内存压力的变化。例如,当系统发出UIApplicationDidReceiveMemoryWarningNotification通知时,应用程序应立即释放不必要的资源。
查看内存使用情况
在 iOS 中,可以使用 mach_task_basic_info 结构体来查看应用的实际内存使用情况。mach_task_basic_info 是一个 task_info 结构体的子集,它提供了关于任务(进程)的基本信息,包括内存使用情况。特别地,你可以通过 phys_footprint 字段来获取应用程序实际占用的物理内存量。
import Foundation
func getMemoryUsage() -> UInt64? {
var info = mach_task_basic_info()
var count = mach_msg_type_number_t(MemoryLayout<mach_task_basic_info>.size) / 4
let kret = withUnsafeMutablePointer(to: &info) { infoPtr in
infoPtr.withMemoryRebound(to: integer_t.self, capacity: 1) { intPtr in
task_info(mach_task_self_, task_flavor_t(MACH_TASK_BASIC_INFO), intPtr, &count)
}
}
if kret == KERN_SUCCESS {
return info.phys_footprint
} else {
print("Failed to get task info with error code \(kret)")
return nil
}
}
// Usage
if let memoryUsage = getMemoryUsage() {
print("Memory usage: \(memoryUsage / 1024 / 1024) MB")
}在这个示例中,mach_task_basic_info 结构体用于存储基本信息,task_info() 函数用来填充这些信息,phys_footprint 字段提供了物理内存占用的实际数据。使用这些底层 API 需要适当的权限,有时可能无法在应用程序的沙盒环境中访问所有内存信息。
在 iOS 中,NSProcessInfo 的 physicalMemory 属性可以用来获取设备的总物理内存大小。这个属性返回一个 NSUInteger 类型的值,表示物理内存的大小(以字节为单位)。这个方法在 iOS 9 及更高版本中可用。
import Foundation
func getPhysicalMemorySize() -> UInt64 {
let physicalMemory = ProcessInfo.processInfo.physicalMemory
return physicalMemory
}
// Usage
let memorySize = getPhysicalMemorySize()
print("Total physical memory: \(memorySize / 1024 / 1024) MB")vm_statistics_data_t 是一个与虚拟内存相关的数据结构,它提供了关于虚拟内存的统计信息,包括系统的内存使用情况。虽然它不能直接提供应用程序使用的内存,但它可以提供有关整个系统的虚拟内存状态的信息。使用 vm_statistics_data_t 可以获取有关系统内存的更详细的统计数据。
import Foundation
import MachO
func getVMStatistics() -> (freeMemory: UInt64, usedMemory: UInt64)? {
var vmStats = vm_statistics_data_t()
var count = mach_msg_type_number_t(MemoryLayout<vm_statistics_data_t>.size) / 4
var hostPort: mach_port_t = mach_host_self()
let result = withUnsafeMutablePointer(to: &vmStats) { vmStatsPtr in
vmStatsPtr.withMemoryRebound(to: integer_t.self, capacity: 1) { intPtr in
// 用于获取主机的统计信息。通过指定 `HOST_VM_INFO`,可以获取虚拟内存相关的数据。
host_statistics(hostPort, HOST_VM_INFO, intPtr, &count)
}
}
if result == KERN_SUCCESS {
let pageSize = vm_kernel_page_size // 系统的页面大小(通常为 4096 字节)。
let freeMemory = UInt64(vmStats.free_count) * UInt64(pageSize)
let usedMemory = (UInt64(vmStats.active_count) + UInt64(vmStats.inactive_count) + UInt64(vmStats.wire_count)) * UInt64(pageSize)
return (freeMemory, usedMemory)
} else {
print("Failed to get VM statistics with error code \(result)")
return nil
}
}
// Usage
if let vmStats = getVMStatistics() {
print("Free memory: \(vmStats.freeMemory / 1024 / 1024) MB")
print("Used memory: \(vmStats.usedMemory / 1024 / 1024) MB")
}vm_statistics_data_t 数据结构包含了有关虚拟内存的统计信息,如 free_count(自由页数)、active_count(活跃页数)、inactive_count(非活跃页数)和 wire_count(被锁定的页数)。
获取可用内存的方法如下:
import Foundation
import MachO
func getAvailableMemory() -> UInt64? {
var vmStats = vm_statistics_data_t()
var count = mach_msg_type_number_t(MemoryLayout<vm_statistics_data_t>.size) / 4
var hostPort: mach_port_t = mach_host_self()
let result = withUnsafeMutablePointer(to: &vmStats) { vmStatsPtr in
vmStatsPtr.withMemoryRebound(to: integer_t.self, capacity: 1) { intPtr in
host_statistics(hostPort, HOST_VM_INFO, intPtr, &count)
}
}
if result == KERN_SUCCESS {
let pageSize = vm_kernel_page_size
let freeMemory = UInt64(vmStats.free_count) * UInt64(pageSize)
let inactiveMemory = UInt64(vmStats.inactive_count) * UInt64(pageSize)
return freeMemory + inactiveMemory
} else {
print("Failed to get VM statistics with error code \(result)")
return nil
}
}
// Usage
if let availableMemory = getAvailableMemory() {
print("Available memory: \(availableMemory / 1024 / 1024) MB")
}free_count 表示系统中未使用的空闲内存页数。inactive_count 表示系统中未使用但可能会重新使用的内存页数。可用内存可以通过将空闲内存和非活跃内存的页数乘以页面大小来计算得到。
造成内存泄漏的常见原因
内存泄漏指的是程序中已动态分配的堆内存由于某些原因未能释放或无法释放,导致系统内存浪费,程序运行速度变慢甚至系统崩溃。
- 循环引用:对象A强引用对象B,对象B又强引用对象A,或多个对象互相强引用形成闭环。使用Weak-Strong Dance、断开持有关系(如使用__block关键字、将self作为参数传入block)。
- Block导致的内存泄漏:Block会对其内部的对象强引用,容易形成循环引用。使用Weak-Strong Dance、断开持有关系(如将self作为参数传入block)。
- NSTimer导致的内存泄漏:NSTimer的target-action机制容易导致self与timer之间的循环引用。在合适的时机销毁NSTimer、使用GCD的定时器、借助中介者(如NSObject对象或NSProxy子类)断开循环引用、使用iOS 10后提供的block方式创建timer。
- 委托模式中的内存泄漏:UITableView的delegate和dataSource、NSURLSession的delegate。根据具体场景选择使用weak或strong修饰delegate属性,或在请求结束时手动销毁session对象。
- 非OC对象的内存管理:CoreFoundation框架下的对象(如CI、CG、CF开头的对象)和C语言中的malloc分配的内存。使用完毕后需手动释放(如CFRelease、free)。
Metrics
Metrics 和 XCTest 中的 memgraph 了解和诊断 Xcode 的内存性能问题。
内存泄漏检测工具原理
内存泄漏指的是程序在运行过程中,分配的内存未能及时释放,导致程序占用的内存持续增加。内存泄漏检测工具的基本原理是监控和管理对象的生命周期,检测那些在生命周期结束后仍未被释放的对象。
FBRetainCycleDetector
FBRetainCycleDetector 是由 Facebook 开源的一个用于检测 iOS 应用中的内存泄漏的工具。内存泄漏通常是由于对象之间的强引用循环导致的,FBRetainCycleDetector 的工作原理就是检测对象图中的强引用循环,进而帮助开发者识别和修复这些泄漏。
FBRetainCycleDetector 的核心思想是通过分析对象之间的引用关系来识别可能的循环引用。它通过以下步骤实现这一点:
- 对象图构建:
FBRetainCycleDetector首先会从一个指定的对象开始,递归地遍历该对象的所有属性和关联对象,构建一个引用图。这个图的节点是对象,边是对象之间的强引用。 - **深度优先搜索 (DFS)**:在构建完对象图之后,
FBRetainCycleDetector会对图进行深度优先搜索,寻找从起始对象到自身的循环路径。换句话说,它会查找路径起始和终止于同一个对象的闭环。 - 循环检测:当找到一个循环路径时,
FBRetainCycleDetector就会将其标记为潜在的内存泄漏。检测到的循环会以易于理解的方式输出,帮助开发者定位和解决问题。
为了避免不必要的检测,FBRetainCycleDetector 允许开发者定义一些属性过滤规则,忽略一些不会导致泄漏的引用。例如,可以跳过一些不可见的系统属性或自定义的非持有性引用。工具能够识别并忽略弱引用(weak或unowned),因为这些引用不会导致内存泄漏。FBRetainCycleDetector 具有较高的灵活性,开发者可以通过扩展和定制对象图的遍历规则,使其适应不同的应用场景和复杂对象结构。由于对象图的遍历和循环检测可能会带来性能开销,FBRetainCycleDetector 主要用于开发和调试阶段,而不建议在生产环境中长期使用。
通常,FBRetainCycleDetector 会在调试时被使用。开发者可以通过简单的代码调用,检测指定对象是否存在循环引用。例如:
FBRetainCycleDetector *detector = [FBRetainCycleDetector new];
[detector addCandidate:someObject];
NSSet *retainCycles = [detector findRetainCycles];通过以上代码,可以查找someObject 是否存在循环引用,并返回检测到的循环路径。
在实际应用中,FBRetainCycleDetector 被广泛用于检测复杂的对象之间的引用关系,特别是在自定义控件、大型视图控制器、网络回调等场景下,容易产生强引用循环的问题。通过早期检测和解决这些循环引用,可以大大提高应用的内存管理效率,减少内存泄漏带来的问题。
MLeaksFinder
MLeaksFinder 是一款由腾讯 WeRead 团队开源的 iOS 内存泄漏检测工具,其原理主要基于对象生命周期的监控和延迟检测机制。
MLeaksFinder 通过为基类 NSObject 添加一个 -willDealloc 方法来监控对象的生命周期。当对象应该被释放时(例如,ViewController 被 pop 或 dismiss 后),该方法被调用。在 -willDealloc 方法中,MLeaksFinder 使用一个弱指针(weak pointer)指向待检测的对象,以避免因为对象已经被释放而导致的野指针访问问题。MLeaksFinder 通过检查视图控制器的生命周期来检测内存泄漏。每个 UIViewController 都有一个 viewDidDisappear 方法,这个方法会在视图控制器从屏幕上消失时被调用。MLeaksFinder 通过在 viewDidDisappear 被调用时,检测该视图控制器是否已经被释放,如果没有被释放则认为存在内存泄漏。对于视图 (UIView),MLeaksFinder 会在视图被从其父视图中移除时(即 removeFromSuperview 调用后)检查视图是否已经被释放。如果视图没有被释放,则认为存在内存泄漏。MLeaksFinder 通过扩展 NSObject 的功能(即为 NSObject 添加一个 Category)来追踪对象的生命周期。当对象的 dealloc 方法没有在预期的时间内被调用时,就可以判断该对象是否泄漏。
在 -willDealloc 方法中,MLeaksFinder 使用 dispatch_after 函数在 GCD(Grand Central Dispatch)的主队列上设置一个延迟(通常是2到3秒)执行的 block。这个 block 在延迟时间后执行,尝试通过之前设置的弱指针访问对象。如果对象已经被释放(即弱指针为 nil),则认为没有内存泄漏;如果对象仍然存活,则认为存在内存泄漏。MLeaksFinder 通过将对象的检测任务加入到下一个 Runloop 中执行,从而避免在当前线程中直接执行检测操作。这种方式确保了不会影响主线程的性能,同时能在适当的时间进行内存泄漏的检测。
如果在延迟时间后对象仍然存活,MLeaksFinder 会执行相应的检测逻辑,并可能通过断言(assertion)中断应用(具体行为可能根据配置和版本有所不同)。MLeaksFinder 会在应用运行时自动检测内存泄漏,不需要开发者手动触发。检测到内存泄漏后,MLeaksFinder 通常会弹出警告框(alert)或通过日志(log)输出相关信息,帮助开发者定位和解决内存泄漏问题。
MLeaksFinder 使用了方法交换技术替换如dismissViewControllerAnimated:completion:等方法,确保释放时触发检测。调用willDealloc方法,设置延时检查对象是否已释放。若未释放,则进入assertNotDealloc方法,中断言提醒开发者。
当 MLeaksFinder 检测到潜在的内存泄漏时,它还可以打印堆栈信息,帮助开发者找出导致对象无法释放的具体代码路径。通过willReleaseChild、willReleaseChildren方法构建子对象的释放堆栈信息。这通常通过递归遍历子对象,并将父对象和子对象的类名组合成视图堆栈(view stack)来实现。
MLeaksFinder 还可能集成了循环引用检测功能,使用如 Facebook 的 FBRetainCycleDetector 这样的工具来找出由 block 等造成的循环引用问题。MLeaksFinder 提供了一种白名单机制,允许开发者将一些特定的对象排除在泄漏检测之外。这在某些对象确实需要持久存在的场景下非常有用。MLeaksFinder 非常轻量,不会显著影响应用的性能。集成简单,自动化检测,极大地方便了开发者发现内存泄漏问题。在某些复杂的情况下,可能会有误报(即认为对象泄漏了,但实际上没有)。
PLeakSniffer
PLeakSniffer是一个用于检测iOS应用程序中内存泄漏的工具。PLeakSniffer的基本工作原理:通过对控制器和视图对象设置弱引用,并使用单例对象周期性地发送ping通知,如果对象在控制器已释放的情况下仍然响应通知,则可能存在内存泄漏。
PLeakSnifferCitizen协议的设计及其在NSObject、UIViewController、UINavigationController和UIView中的实现。每个类都通过实现prepareForSniffer方法来挂钩适当的生命周期方法(如viewDidAppear、pushViewController等),在适当的时机调用markAlive方法,将代理对象附加到被监测的对象上,以便后续的ping操作能够检测到对象的存活状态。
代理对象PObjectProxy的功能,它主要负责接收ping通知并检查宿主对象是否应当被释放,如果检测到可能的内存泄漏,就会触发警报或打印日志。通过这种方式,PLeakSniffer能够在运行时检测到iOS应用中可能存在的内存泄漏问题。
其他内存泄漏检测工具
hook malloc方法
要在 iOS 上 hook malloc 方法可以监控内存分配。可以使用函数拦截技术。以下是一个示例,展示如何使用 Fishhook 库来 hook malloc 方法。
将 Fishhook 库添加到你的项目中。你可以通过 CocoaPods 或手动添加 Fishhook 源代码。
#import <Foundation/Foundation.h>
#import <malloc/malloc.h>
#import "fishhook.h"
// 原始 malloc 函数指针
static void* (*original_malloc)(size_t size);
// 自定义 malloc 函数
void* custom_malloc(size_t size) {
void *result = original_malloc(size);
NSLog(@"Allocated %zu bytes at %p", size, result);
return result;
}
// Hook 函数
void hookMalloc() {
// 重新绑定 malloc 函数
rebind_symbols((struct rebinding[1]){{"malloc", custom_malloc, (void *)&original_malloc}}, 1);
}
int main(int argc, const char * argv[]) {
@autoreleasepool {
// Hook malloc
hookMalloc();
// 测试 malloc 和 free
void *ptr = malloc(1024);
free(ptr);
}
return 0;
}在实际项目中使用时,注意性能开销和日志记录的影响。
malloc logger
malloc_logger 是 iOS 和 macOS 中用于内存分配调试的一个工具。它允许开发者设置一个自定义的日志记录器函数,以便在内存分配和释放操作发生时记录相关信息。通过使用 malloc_logger,开发者可以更容易地检测和诊断内存问题,如内存泄漏、过度分配等。
以下是一个使用 Objective-C 实现的示例,展示如何设置和使用 malloc_logger:
#import <Foundation/Foundation.h>
#import <malloc/malloc.h>
// 定义自定义的 malloc logger 函数
void custom_malloc_logger(uint32_t type, uintptr_t arg1, uintptr_t arg2, uintptr_t result, uintptr_t num_bytes) {
switch (type) {
case MALLOC_LOG_TYPE_ALLOCATE:
NSLog(@"Allocated %lu bytes at %p", (unsigned long)num_bytes, (void *)result);
break;
case MALLOC_LOG_TYPE_DEALLOCATE:
NSLog(@"Deallocated memory at %p", (void *)arg1);
break;
case MALLOC_LOG_TYPE_HAS_ZONE:
NSLog(@"Memory operation with zone at %p", (void *)arg1);
break;
default:
break;
}
}
// 设置自定义的 malloc logger
void setCustomMallocLogger() {
malloc_logger = custom_malloc_logger;
}
int main(int argc, const char * argv[]) {
@autoreleasepool {
// 设置自定义 malloc logger
setCustomMallocLogger();
// 测试 malloc 和 free
void *ptr = malloc(1024);
free(ptr);
}
return 0;
}在这个示例中,我们定义了一个自定义的 malloc_logger 函数 custom_malloc_logger,并在 setCustomMallocLogger 函数中将其设置为当前的 malloc_logger。然后,在 main 函数中,我们测试了内存的分配和释放操作,并通过日志记录器记录这些操作的信息。
通过这种方式,开发者可以在内存分配和释放时记录相关信息,从而更好地理解和优化应用程序的内存使用情况。
内存快照检测方案
扫描进程中所有Dirty内存,建立内存节点之间的引用关系有向图,用于内存问题的分析定位。
在 iOS 中,可以使用 vm_region_recurse_64 函数来获取所有内存区域的信息。
#include <stdio.h>
#include <stdlib.h>
#include <mach/mach.h>
#include <mach/vm_map.h>
int main(int argc, const char * argv[]) {
mach_port_t task = mach_task_self();
vm_address_t address = VM_MIN_ADDRESS;
vm_size_t size = VM_MAX_ADDRESS - VM_MIN_ADDRESS;
vm_region_basic_info_data_64_t info;
mach_msg_type_number_t info_count = VM_REGION_BASIC_INFO_COUNT_64;
memory_object_name_t object_name;
mach_port_t object_handle;
kern_return_t kr;
while (size > 0) {
kr = vm_region_recurse_64(task, &address, &size, VM_REGION_BASIC_INFO,
(vm_region_info_t)&info, &info_count, &object_name,
&object_handle);
if (kr != KERN_SUCCESS)
break;
printf("Address: 0x%llx, Size: 0x%llx, Protection: 0x%x, In Use: %s\n",
(unsigned long long)info.protection,
(unsigned long long)info.size,
(unsigned int)info.protection,
info.is_submap ? "Yes" : "No");
address += info.size;
size -= info.size;
}
if (kr != KERN_SUCCESS) {
char *err = mach_error_string(kr);
fprintf(stderr, "vm_region_recurse_64 failed: %s\n", err);
free(err);
}
return 0;
}在iOS中,可以使用libmalloc库提供的malloc_get_all_zones函数来获取所有内存区域(zone)的信息。malloc_get_all_zones可以遍历所有的内存区域,并为每个区域执行一个回调函数,从而获取详细的内存分配信息。
以下是一个简单的代码示例,展示如何使用malloc_get_all_zones来获取并打印内存区域的信息:
#import <malloc/malloc.h>
#import <mach/mach.h>
// 自定义的回调函数,用于处理每个内存区域的块。该函数用于处理每个zone中的内存块,在这个例子中,它简单地打印出每个内存块的地址和大小。
void my_zone_enumerator(task_t task, void *context, unsigned type_mask, vm_range_t *ranges, unsigned range_count) {
for (unsigned i = 0; i < range_count; i++) {
printf("Memory range: 0x%llx, Size: %llu\n", ranges[i].address, ranges[i].size);
}
}
void print_all_zones() {
// 获取当前任务的mach port。用于获取当前任务的Mach端口,这对于与Mach内核通信是必需的。
task_t task = mach_task_self();
unsigned int count;
// 这是`libmalloc`库中的一个结构体,表示内存区域。通过调用其`introspect`属性下的`enumerator`函数,可以遍历该zone中的所有内存块。
malloc_zone_t **zones = NULL;
// 获取所有的内存区域。这个函数返回当前任务的所有内存区域(zone),这些zone通常对应于不同的分配器或内存池。
kern_return_t kr = malloc_get_all_zones(task, NULL, &zones, &count);
if (kr != KERN_SUCCESS) {
fprintf(stderr, "Error: Unable to get all zones\n");
return;
}
// 遍历所有的zone
for (unsigned int i = 0; i < count; i++) {
malloc_zone_t *zone = zones[i];
if (zone != NULL) {
printf("Zone name: %s\n", zone->zone_name);
// 枚举zone中的内存块
zone->introspect->enumerator(task, NULL, MALLOC_PTR_IN_USE_RANGE_TYPE, (vm_address_t)zone, my_zone_enumerator);
}
}
}
int main(int argc, const char * argv[]) {
print_all_zones();
return 0;
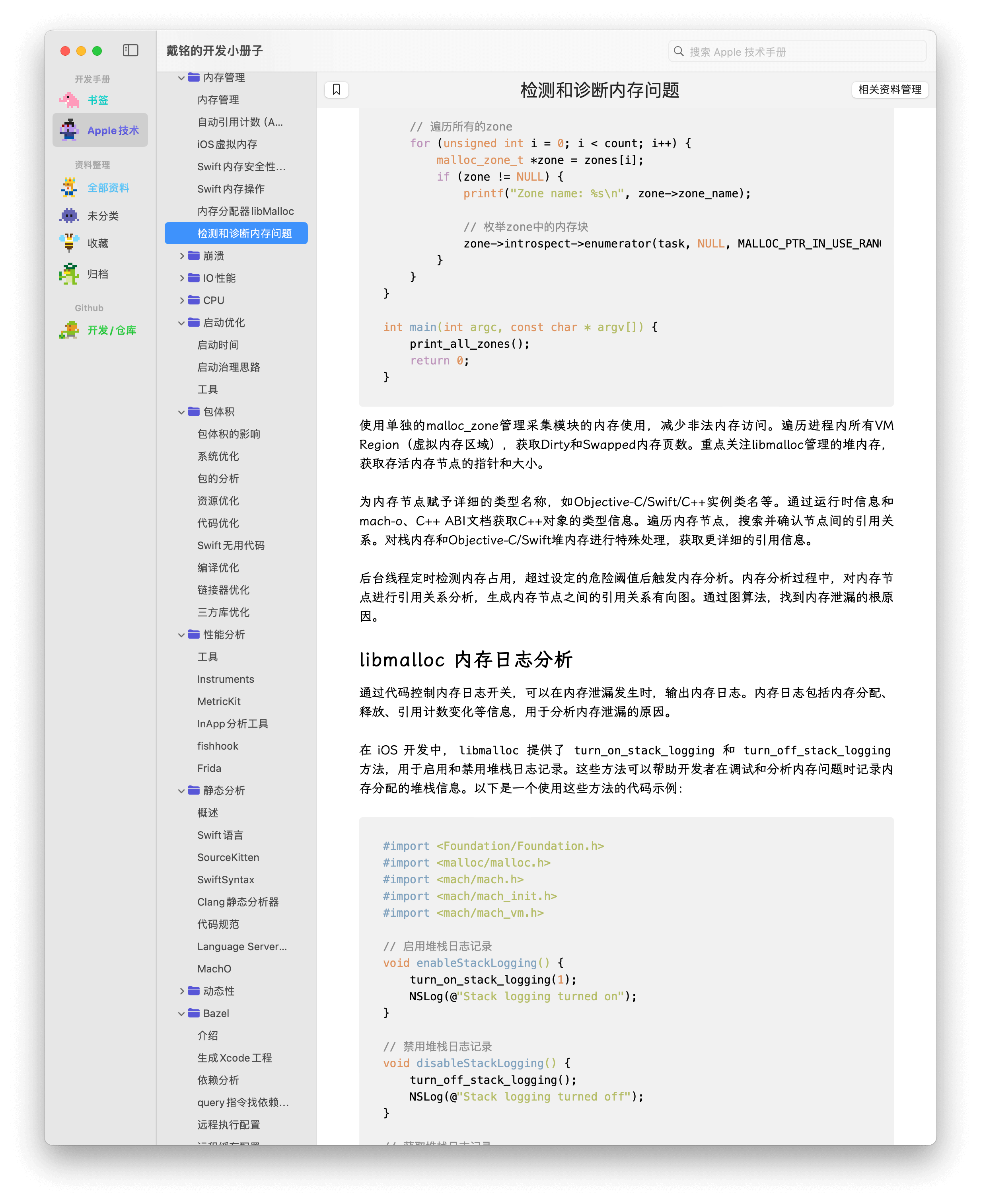
}使用单独的 malloc_zone 管理采集模块的内存使用,减少非法内存访问。遍历进程内所有VM Region(虚拟内存区域),获取Dirty和Swapped内存页数。重点关注libmalloc管理的堆内存,获取存活内存节点的指针和大小。
为内存节点赋予详细的类型名称,如Objective-C/Swift/C++实例类名等。通过运行时信息和mach-o、C++ ABI文档获取C++对象的类型信息。遍历内存节点,搜索并确认节点间的引用关系。对栈内存和Objective-C/Swift堆内存进行特殊处理,获取更详细的引用信息。
后台线程定时检测内存占用,超过设定的危险阈值后触发内存分析。内存分析过程中,对内存节点进行引用关系分析,生成内存节点之间的引用关系有向图。通过图算法,找到内存泄漏的根原因。
libmalloc 内存日志分析
通过代码控制内存日志开关,可以在内存泄漏发生时,输出内存日志。内存日志包括内存分配、释放、引用计数变化等信息,用于分析内存泄漏的原因。
在 iOS 开发中,libmalloc 提供了 turn_on_stack_logging 和 turn_off_stack_logging 方法,用于启用和禁用堆栈日志记录。这些方法可以帮助开发者在调试和分析内存问题时记录内存分配的堆栈信息。以下是一个使用这些方法的代码示例:
#import <Foundation/Foundation.h>
#import <malloc/malloc.h>
#import <mach/mach.h>
#import <mach/mach_init.h>
#import <mach/mach_vm.h>
// 启用堆栈日志记录
void enableStackLogging() {
turn_on_stack_logging(1);
NSLog(@"Stack logging turned on");
}
// 禁用堆栈日志记录
void disableStackLogging() {
turn_off_stack_logging();
NSLog(@"Stack logging turned off");
}
// 获取堆栈日志记录
void getStackLoggingRecords() {
// 获取当前任务
task_t task = mach_task_self();
// 获取所有堆栈日志记录
mach_vm_address_t *records;
uint32_t count;
kern_return_t kr = __mach_stack_logging_enumerate_records(task, &records, &count);
if (kr != KERN_SUCCESS) {
NSLog(@"Failed to enumerate stack logging records: %s", mach_error_string(kr));
return;
}
for (uint32_t i = 0; i < count; i++) {
mach_vm_address_t record = records[i];
NSLog(@"Record %u: %p", i, (void *)record);
// 定义堆栈帧数组
uint64_t frames[128];
// 获取堆栈帧信息
uint32_t frameCount = __mach_stack_logging_frames_for_uniqued_stack(task, record, frames, 128);
// 遍历堆栈帧,每次循环中,获取当前堆栈帧地址并打印地址信息
for (uint32_t j = 0; j < frameCount; j++) {
NSLog(@"Frame %u: %p", j, (void *)frames[j]);
}
}
// 释放记录数组
vm_deallocate(task, (vm_address_t)records, count * sizeof(mach_vm_address_t));
}
// 示例函数,分配一些内存
void allocateMemory() {
void *ptr1 = malloc(1024);
void *ptr2 = malloc(2048);
free(ptr1);
free(ptr2);
}
// 主函数
int main(int argc, const char * argv[]) {
@autoreleasepool {
// 启用堆栈日志记录
enableStackLogging();
// 分配内存
allocateMemory();
// 获取堆栈日志记录
getStackLoggingRecords();
// 禁用堆栈日志记录
disableStackLogging();
}
return 0;
}在这个示例中,我们首先调用 turn_on_stack_logging 方法来启用堆栈日志记录,然后进行一些内存分配和释放操作。接着,我们调用 __mach_stack_logging_enumerate_records 方法获取所有堆栈日志记录,并使用 __mach_stack_logging_frames_for_uniqued_stack 方法解析每个日志记录以获取堆栈帧信息。最后,我们调用 turn_off_stack_logging 方法来禁用堆栈日志记录。
通过这种方式,开发者可以在需要时启用和禁用堆栈日志记录,并解析这些日志记录以获取详细的堆栈信息。需要注意的是,这些函数在实际项目中使用时,需要确保在合适的时机启用和禁用堆栈日志记录,以避免性能开销和不必要的日志记录。
IO 性能
文件写操作常见但易出错。常见问题包括数据不一致、数据丢失、性能波动等。
读写的 API
文件读写系统调用的 API 有 read() 和 write()。read()从文件读取数据到应用内存。write()将数据从应用内存写入文件到内核缓存,但不保证立即写入磁盘。mmap()将文件映射到应用内存,直接访问,但写操作同样先进入内核缓存。fsync() 和 fcntl(F_FULLSYNC) 会强制将文件写入磁盘。c标准库提供的文件读写 API 是 fwrite(buffer, sizeof(char), size, file_pointer) 和 fflush(file_pointer)。
iOS 提供了 NSFileManager 的 replaceItemAtURL:withItemAtURL:backupItemName:options:resultingItemURL:error: 方法,可以实现原子性操作。
flock 或 fcntl 使用文件锁防止多个进程或线程同时写入同一个文件,避免产生竞争条件,保证数据一致性。
iOS 提供了 NSFileManager 和 NSData 的封装方法,通常比直接使用 POSIX API 更安全和高效。
测试文件I/O性能时,应通过 fcntl(fd, F_NOCACHE, 1) 禁用统一缓冲缓存(UBC),以避免缓存影响测试结果。
文件缓存
文件缓存可以帮助优化应用性能、减少网络请求和延长电池续航。
iOS 提供了多个文件存储目录,选择合适的目录有助于管理缓存文件的生命周期。包括Caches 目录和tmp 目录。Caches 目录适合存储缓存文件。系统可能会在磁盘空间紧张时清除这个目录下的文件,因此不应存储重要数据。可以通过 NSSearchPathForDirectoriesInDomains(.cachesDirectory, .userDomainMask, true) 获取路径。tmp 目录适用于临时文件。系统重启或应用未运行时,可能会清除这个目录下的文件。可以通过 NSTemporaryDirectory() 获取路径。
根据数据的重要性和更新频率,制定缓存策略。为缓存数据设置时间戳或过期时间。每次读取缓存时检查数据是否过期,及时更新。实现 LRU 算法,定期清理最久未使用的缓存文件。
为缓存文件生成唯一标识符(如使用哈希值),避免文件名冲突。可以将 URL 的 MD5 或 SHA1 哈希值作为缓存文件名。将缓存文件按类别或特定属性进行分类存储,方便管理。例如,将图片和JSON数据分别存储在不同的子目录中。
对于大型缓存数据,可以在写入文件时使用 GZIP 等压缩技术,减少存储空间占用。iOS 的 NSData 和 NSFileManager 支持数据的压缩和解压缩。避免在主线程上执行缓存读写操作,使用 Swift Concurrency 将缓存操作移到后台,保持 UI 的流畅性。减少频繁的写入操作,可以将多次写入合并为一次批量操作。
对于敏感数据(如用户信息),应在缓存时进行加密处理。iOS 提供了 Keychain 进行安全存储,也可以使用 CommonCrypto 框架进行自定义加密。
定期清理过期或不再使用的缓存文件,避免占用过多磁盘空间。可以使用 iOS 的 NSURLCache 设置缓存大小限制,自动管理缓存清理。提供手动清理缓存的选项,允许用户在应用内清理缓存数据。根据数据更新频率设置缓存失效时间,确保用户获得最新数据。可以通过 ETag 或 Last-Modified HTTP 头实现增量更新,避免每次都下载完整数据。尽量利用 iOS 自带的缓存机制,例如 NSURLCache,它自动管理 HTTP 请求的缓存,支持内存和磁盘缓存。对于图片缓存,使用 NSCache 或者第三方库,可以在内存和磁盘之间自动管理图片的缓存。
mmap
mmap 是一种内存映射文件的机制,允许用户态的程序像操作内存一样直接操作磁盘文件。通过 mmap,文件的内容被映射到进程的地址空间中,程序可以直接读写这段地址空间,操作系统会在背后处理实际的磁盘读写操作。标准IO(如read/write)涉及系统调用和内存拷贝开销,数据需要在内核态和用户态之间来回拷贝。mmap 避免了这些开销,因为它直接在用户态的内存中操作,操作系统只在需要时(如缺页中断)介入处理磁盘读写。
对于超过物理内存大小的大文件,mmap 可以利用虚拟内存的特性,在有限的物理内存中处理大文件。多个进程可以映射同一个文件到各自的地址空间,实现内存共享,这在动态链接库等场景中非常有用。在某些场景下,mmap 可以提供更好的性能,因为它减少了系统调用和内存拷贝的次数。但具体性能取决于应用场景和操作系统实现。在处理大文件时,mmap 可以避免频繁的内存拷贝和磁盘I/O操作。多个进程可以共享同一个动态链接库,节省内存和磁盘空间。可用于实现高效的内存文件交换,如数据库中的内存映射文件。
mmap 也有些问题需要注意。当访问的页面不在物理内存中时,会发生缺页中断,这会有一定的性能开销。为了维护地址空间与文件的映射关系,内核需要额外的数据结构,这也会带来一定的性能开销。
我们使用 mmap 将文件映射到内存中,并读取文件内容。示例如下:
#import <Foundation/Foundation.h>
#import <sys/mman.h>
#import <fcntl.h>
#import <unistd.h>
void mmapExample() {
// 文件路径
NSString *filePath = @"/path/to/your/file.txt";
// 打开文件
int fd = open([filePath UTF8String], O_RDONLY);
if (fd == -1) {
NSLog(@"Failed to open file");
return;
}
// 获取文件大小
off_t fileSize = lseek(fd, 0, SEEK_END);
if (fileSize == -1) {
NSLog(@"Failed to get file size");
close(fd);
return;
}
// 将文件映射到内存
void *mappedFile = mmap(NULL, fileSize, PROT_READ, MAP_PRIVATE, fd, 0);
if (mappedFile == MAP_FAILED) {
NSLog(@"Failed to map file");
close(fd);
return;
}
// 关闭文件描述符
close(fd);
// 读取文件内容
NSData *fileData = [NSData dataWithBytes:mappedFile length:fileSize];
NSString *fileContent = [[NSString alloc] initWithData:fileData encoding:NSUTF8StringEncoding];
NSLog(@"File content: %@", fileContent);
// 解除文件映射
if (munmap(mappedFile, fileSize) == -1) {
NSLog(@"Failed to unmap file");
}
}
int main(int argc, const char * argv[]) {
@autoreleasepool {
mmapExample();
}
return 0;
}MMKV 是腾讯开源的一个高性能通用键值对存储库,基于 mmap 内存映射机制,它提供了简单易用的接口,支持高效的读写操作,并且支持数据加密。
以下是一个在 iOS 项目中使用 MMKV 的示例代码:
import UIKit
import MMKV
@UIApplicationMain
class AppDelegate: UIResponder, UIApplicationDelegate {
var window: UIWindow?
func application(_ application: UIApplication, didFinishLaunchingWithOptions launchOptions: [UIApplication.LaunchOptionsKey: Any]?) -> Bool {
// 初始化 MMKV
MMKV.initialize(rootDir: MMKV.defaultMMKVPath)
return true
}
}使用 MMKV 存储和读取数据
import MMKV
func mmkvExample() {
// 获取默认的 MMKV 实例
let mmkv = MMKV.default()
// 存储数据
mmkv?.set("Inception", forKey: "movieTitle")
mmkv?.set(8.8, forKey: "movieRating")
// 读取数据
if let movieTitle = mmkv?.string(forKey: "movieTitle") {
print("Movie Title: \(movieTitle)")
}
let movieRating = mmkv?.double(forKey: "movieRating")
print("Movie Rating: \(movieRating ?? 0.0)")
}
mmkvExample()NSData 提供了三个与 mmap 相关的读取选项,它们分别是:
NSDataReadingUncached:这个选项表示不要缓存数据,如果文件只需要读取一次,使用这个选项可以提高性能。这个选项与 mmap 没有直接关系,因为它不涉及内存映射。NSDataReadingMappedIfSafe:这个选项表示在保证安全的前提下,如果条件允许,则使用 mmap 进行内存映射。这意味着如果文件位于固定磁盘(非可移动磁盘或网络磁盘),则可能会使用 mmap 来优化读取性能。NSDataReadingMappedAlways:这个选项表示总是使用 mmap 进行内存映射,不考虑文件的具体存储位置。但是,在 iOS 上,由于所有应用都运行在沙盒中,对 iOS 而言,NSDataReadingMappedIfSafe和NSDataReadingMappedAlways通常是等价的,因为 iOS 设备上的文件存储通常都是在固定磁盘上。
当你需要读取一个较大的文件,但又不想一次性将整个文件加载到内存中时,可以使用 NSData 的 dataWithContentsOfFile:options:error: 方法,并传入上述与 mmap 相关的选项之一。以下是一个示例代码,展示了如何使用 NSDataReadingMappedIfSafe 选项来读取文件:
NSError *error = nil;
NSData *data = [NSData dataWithContentsOfFile:filePath options:NSDataReadingMappedIfSafe error:&error];
if (data == nil) {
// 处理错误
NSLog(@"Error reading file: %@", error.localizedDescription);
} else {
// 成功读取文件,可以处理 data
}在这个例子中,filePath 是你想要读取的文件的路径。通过使用 NSDataReadingMappedIfSafe,系统会在可能的情况下使用 mmap 来映射文件,这样就不需要在内存中为整个文件分配空间,从而减少了内存的使用。然而,需要注意的是,虽然 mmap 减少了物理内存的使用,但它仍然需要消耗虚拟内存地址空间。
在用 mmap 时要注意如果使用 mmap 映射了文件,那么在 NSData 的生命周期内,你不能删除或修改对应的文件,因为这可能会导致内存映射失效,进而引发不可预见的错误。mmap 适用于那些需要频繁读取、但不需要同时读取整个文件内容的场景,如视频加载、大日志文件读取等。mmap 映射的区域大小会占用相应大小的虚拟内存地址空间,因此对于非常大的文件,可能不适合将整个文件映射到内存中。
CPU
CPU 的高占用,会让手机耗电变快。
[NSProcessInfo processInfo].activeProcessorCount 可以获取 CPU 核数。获取 CPU 类型的方法有 sysctl、uname、hw.machine 和 NXArchInfo 几种方法。
怎么获取 CPU 使用率呢?
在 iOS 的 Mach 层中,thread_basic_info 结构体用于提供有关线程的一些基本信息,其中就有线程CPU使用率。这个结构体定义在 <mach/thread_info.h> 头文件中,其包含的字段提供了关于线程运行状态、执行时间和其他统计信息的基本数据。以下是 thread_basic_info 结构体的详细定义及其各字段的解释:
struct thread_basic_info {
time_value_t user_time; // 用户模式下线程运行的总时间
time_value_t system_time; // 内核模式下线程运行的总时间
integer_t cpu_usage; // CPU 使用率,以百分之一为单位
policy_t policy; // 调度策略(例如FIFO、Round Robin等)
integer_t run_state; // 线程的运行状态
integer_t flags; // 线程的标志位(例如是否正在被调度)
integer_t suspend_count; // 线程被挂起的次数
integer_t sleep_time; // 线程的睡眠时间
};字段解释
user_time: 该字段表示线程在用户模式下(即执行用户空间的代码)运行的总时间。time_value_t是一个结构体,通常表示为秒和微秒。system_time: 该字段表示线程在系统模式下(即执行内核空间的代码)运行的总时间。cpu_usage: 该字段表示线程的 CPU 使用率,以百分之一为单位。例如,如果值为 100,表示线程使用了 1% 的 CPU 时间。policy: 该字段表示线程的调度策略,如固定优先级调度(FIFO)或轮转调度(Round Robin)等。run_state: 该字段表示线程当前的运行状态。可能的值包括:TH_STATE_RUNNING: 正在运行TH_STATE_STOPPED: 已停止TH_STATE_WAITING: 正在等待资源TH_STATE_UNINTERRUPTIBLE: 不可中断的等待TH_STATE_HALTED: 已终止
flags: 该字段包含一些线程的标志位,用来表示线程的某些状态特性。例如,线程是否正在被调度等。suspend_count: 该字段表示线程当前被挂起的次数。挂起次数大于 0 时,线程不会被调度执行。sleep_time: 该字段表示线程处于睡眠状态的时间。
这些信息对于性能分析、调试以及获取系统中线程的运行状况非常有用。通过使用 thread_info 函数,可以获取到某个特定线程的 thread_basic_info 结构体实例。
要获取当前应用的 CPU 占用率,可以通过遍历当前应用的所有线程,利用 thread_info 函数获取每个线程的 CPU 使用情况。然后,将所有线程的 CPU 使用率汇总,就能得到整个应用的 CPU 占用率。
下面是一个使用 Objective-C 编写的示例代码,展示了如何获取当前应用的 CPU 占用率:
#import <mach/mach.h>
#import <assert.h>
float cpu_usage() {
kern_return_t kr;
thread_array_t thread_list;
mach_msg_type_number_t thread_count;
thread_info_data_t thread_info_data;
mach_msg_type_number_t thread_info_count;
// 获取当前任务
task_t task = mach_task_self();
// task_threads 这个函数用于获取当前任务的所有线程。`thread_list` 包含了所有线程的 ID,`thread_count` 是线程的数量。
kr = task_threads(task, &thread_list, &thread_count);
if (kr != KERN_SUCCESS) {
return -1;
}
float total_cpu = 0;
// 遍历所有线程
for (int i = 0; i < thread_count; i++) {
thread_info_count = THREAD_INFO_MAX;
// 通过 thread_info 获取每个线程的 `thread_basic_info`,其中包含了线程的 CPU 使用信息。
kr = thread_info(thread_list[i], THREAD_BASIC_INFO, (thread_info_t)thread_info_data, &thread_info_count);
if (kr != KERN_SUCCESS) {
return -1;
}
thread_basic_info_t thread_info = (thread_basic_info_t)thread_info_data;
if (!(thread_info->flags & TH_FLAGS_IDLE)) {
// 通过 `thread_basic_info` 结构体中的 `cpu_usage` 字段获取每个线程的 CPU 使用率,并将它们相加以得到整个应用的 CPU 使用率。
total_cpu += thread_info->cpu_usage / (float)TH_USAGE_SCALE * 100.0;
}
}
// 用于释放之前分配的线程列表内存。
kr = vm_deallocate(task, (vm_address_t)thread_list, thread_count * sizeof(thread_t));
assert(kr == KERN_SUCCESS);
return total_cpu;
}CPU 占用率是一个瞬时值,通常会波动,因此在实际应用中,可能需要多次采样并取平均值来得到更稳定的结果。这个方法会占用一定的 CPU 资源,尤其是在应用包含大量线程时,所以建议在非主线程或低优先级任务中执行这类操作。
对于总 CPU 占用率,使用 host_statistics 函数获取 host_cpu_load_info 结构体中的 cpu_ticks 值来计算总的 CPU 占用率。cpu_ticks 是一个数组,包含了 CPU 在各种状态(如用户模式、系统模式、空闲、Nice 等)下运行的时钟脉冲数量。通过计算这些脉冲数量的变化,可以得出总的 CPU 占用率。
以下是一个完整的示例代码,展示了如何使用 host_statistics 函数来计算总的 CPU 占用率:
#import <mach/mach.h>
#import <stdio.h>
float cpu_usage() {
// 获取 host 的 CPU load 信息
host_cpu_load_info_data_t cpuInfo;
mach_msg_type_number_t count = HOST_CPU_LOAD_INFO_COUNT;
// `host_statistics` 这是一个用于获取主机统计信息的函数。通过传递 `HOST_CPU_LOAD_INFO` 作为参数,可以获取 `host_cpu_load_info_data_t` 结构体,该结构体包含了 CPU 在不同状态下的时钟脉冲数。
kern_return_t kr = host_statistics(mach_host_self(), HOST_CPU_LOAD_INFO, (host_info_t)&cpuInfo, &count);
if (kr != KERN_SUCCESS) {
return -1;
}
// 获取各个状态下的 CPU 时钟脉冲数。通过将 `cpu_ticks` 数组中的所有值相加,得到 CPU 所有状态下运行的总时钟脉冲数。
unsigned long long totalTicks = 0;
for (int i = 0; i < CPU_STATE_MAX; i++) {
totalTicks += cpuInfo.cpu_ticks[i];
}
// 计算 CPU 占用率
unsigned long long idleTicks = cpuInfo.cpu_ticks[CPU_STATE_IDLE]; // `cpu_ticks[CPU_STATE_IDLE]` 表示 CPU 在空闲状态下的时钟脉冲数。
float cpuUsage = (1.0 - ((float)idleTicks / (float)totalTicks)) * 100.0;
return cpuUsage;
}这种方法计算的是整个系统的 CPU 占用率,而不是某个具体应用的 CPU 占用率。如果需要获取具体应用的 CPU 使用情况,应该使用 thread_info 等方法。
启动优化
移动应用的启动时间是影响用户体验的重要方面。
启动时间
识别启动阶段各个步骤的耗时情况。
启动分为以下三种:
- Cold Launch:应用完全从零开始加载,最耗时。
- Warm Launch:应用仍在内存中,但由于系统资源紧张,部分内容可能被清理,需要重新加载。
- Hot Launch:应用仍在后台,只需快速恢复。
治理主要是针对 Cold Landch。
示例:
import UIKit
class AppDelegate: UIResponder, UIApplicationDelegate {
var window: UIWindow?
var launchTime: CFAbsoluteTime?
func application(_ application: UIApplication, didFinishLaunchingWithOptions launchOptions: [UIApplication.LaunchOptionsKey: Any]?) -> Bool {
// 记录应用启动的时间
launchTime = CFAbsoluteTimeGetCurrent()
// 在主线程完成所有启动任务后,计算应用启动时间
DispatchQueue.main.asyncAfter(deadline: .now() + 0.1) {
if let launchTime = self.launchTime {
let launchDuration = CFAbsoluteTimeGetCurrent() - launchTime
print("App launch time: \(launchDuration) seconds")
}
}
return true
}
}另外也可获取完整加载使用时间。使用 DispatchQueue.main.asyncAfter 延迟执行,以确保所有启动任务(如 UI 渲染、网络请求等)已经完成。然后再使用 CFAbsoluteTimeGetCurrent() 获取当前时间,与记录的启动时间相减,得到启动耗时。
使用 mach_absolute_time() 来计算时间:
static uint64_t startTime;
static uint64_t endTime = -1;
static mach_timebase_info_data_t timebaseInfo;
static inline NSTimeInterval MachTimeToSeconds(uint64_t machTime) {
return ((machTime / 1e9) * timebaseInfo.numer) / timebaseInfo.denom;
}
@implementation DurationTracker
+ (void)load {
startTime = mach_absolute_time();
mach_timebase_info(&timebaseInfo);
@autoreleasepool {
__block id<NSObject> observer;
observer = [[NSNotificationCenter defaultCenter] addObserverForName:UIApplicationDidFinishLaunchingNotification
object:nil queue:nil
usingBlock:^(NSNotification *note) {
dispatch_async(dispatch_get_main_queue(), ^{
endTime = mach_absolute_time();
NSLog(@"StartupMeasurer: it took %f seconds until the app could respond to user interaction.", MachTimeToSeconds(endTime - startTime));
});
[[NSNotificationCenter defaultCenter] removeObserver:observer];
}];
}
}启动治理思路
减少初始加载的工作量主要有延迟初始化、按需加载数据和优化依赖注入。减少不必要的资源加载的方式有移除未使用的资源和使用延迟加载。减少动态库的数量,避免在启动时过度使用复杂的泛型或协议扩展,因为这些特性可能会增加编译器在运行时的解析开销。使用 Swift Concurrency 将耗时操作异步化,以并行处理更多任务,减少主线程的压力。减少初始界面上的复杂视图层次结构,优先加载并显示关键内容,延迟非关键内容的加载。在启动时尽量减少复杂的动画过渡,以提升首屏的渲染速度。
打法上:
- 删:出最小集,减任务
- 延:按需,延到首页后
- 并:统一管理,编排,充分利用多核
- 快:减 I/O,少并发,少计算(缓存)
经验:
- 动态库转静态库
- 不链用不到的系统库
- 懒加载动态库,动态取类,dlopen 动态库
+load里任务挪地- 减少视图数,少层级,懒加载
- 主线程等待的子线程设高优先级
- 子线程预加载
- 文件大拆小,碎合并
- 统计高频调用方法
- 警惕隐藏的全局锁
包体积
影响和手段
包体积优化的必要性:
- 下载转化率下降:每增加6M,应用下载转化率下降1%。
- App Store限制:超过200MB的包,iOS 13以下用户无法通过蜂窝数据下载,iOS 13及以上用户需手动设置。
- 磁盘占用:大包体积占用更多存储空间,影响低存储用户。
- 用户下载意愿:大包体积减少用户下载意愿,尤其在蜂窝数据低数据模式下。
- 性能影响:包体积大增加启动时间和SIGKILL风险,降低基础体验。
技术方案主要是以下几种:
- 资源优化:优化大块资源、无用配置文件和重复资源。
- 工程架构优化:建立体积检测流水线,控制体积增长。
- 图片优化:无用图片优化、Asset Catalog优化、HEIC和WebP压缩优化、TinyPng压缩。
- 编译器优化:使用LLVM编译选项,进行OC、C++、Swift等语言的编译优化。
- 代码优化:无用类、方法、模块瘦身,精简重复代码,AB实验固化。
效果上讲,工程方向优化大于资源优化,资源优化大于代码优化。
系统提供的方式有
- App Thinning:利用Apple提供的App Thinning功能,根据用户的设备自动下载适合该设备的资源包,有助于减少初装包的大小。
- 按需下载资源:使用On-Demand Resources来按需下载资源,只下载用户实际需要的部分,从而减小初始安装包的大小。
包分析
iOS端安装包组成部分有:
- Mach-O文件:iOS系统上的可执行文件。
- Watch APP:带有小组件功能的WatchApp。
- 自定义动态库:动态库推迟到运行时加载,节省代码段空间。
- Swift系统库:高版本iOS系统自带,低版本需iPA包中自带。
- Assets资源:Assets.car文件,包含图片资源。
- 根目录下图片资源:直接添加进工程的图片文件。
- bundle资源:管理图片和其他配置文件。
- 其他配置文件:如plist、js、css、json等。
Mach-O是Mach Object文件格式的缩写,用于记录Mac及iOS系统上的可执行文件、目标代码、动态库和内存转储。使用MachOView和otool命令查看Mach-O文件信息,以及通过file和lipo命令查看文件格式和架构。Mach-O文件有Header、LoadCommands和Data部分,特别是LoadCommands中的关键cmd类型如LC_SEGMENT_64,及其段(__PAGEZERO、__TEXT、__DATA、__LINKEDIT)。
APPAnalyze 是一款用于分析iOS ipa包的脚本工具,能够自动扫描并发现可修复的包体积问题,同时生成包体积数据用于查看。
资源优化
资源优化方案有图片压缩、资源清理、动态加载资源、使用 Assets.xcassets 等。
Asset Catalog是Xcode提供的资源管理工具,用于集中管理项目中的图片等资源。通过Xcode自带工具actool生成Assets.car文件,可使用assetutil工具分析文件内容。开发者在图片放入Asset Catalog前不要做无损压缩,因为actool会重新进行压缩处理。
Asset Catalog 的优点有:
- 包体积瘦身:根据不同设备下载匹配的图片资源,减少下载包大小。
- 统一的图片无损压缩:采用Apple Deep Pixel Image Compression技术,提高压缩比。
- 便利的资源管理:将图片资源统一压缩成Assets.car文件,便于管理。
- 高效的I/O操作:图片加载耗时减少两个数量级,提升应用性能。
代码优化
方案有:
- 移除未使用的代码:查找并删除未使用的类、方法、变量等。审查业务逻辑,删除不再使用或已被废弃的代码模块。
- 重构代码:对重复的代码进行重构,使用函数、类等方法来减少代码冗余。优化数据结构,减少内存占用和CPU消耗。
- 编译策略调整:修改编译策略,如启用LTO(链接时优化)来优化跨模块调用代码。剥离符号表(Strip Linked Product),删除未引用的C/C++/Swift代码。精简编译产物,只保留必要的符号和导出信息。
- 代码组件化:将常用代码文件打包成静态库,切断不同业务代码之间的依赖,减少每次编译的代码量。
- 减少文件引用:能使用
@class就使用@class,尽量减少文件之间的直接引用关系。 - 减少Storyboard和XIB文件的使用:尽量使用代码布局,减少Storyboard和XIB文件的使用,这些文件在编译时会增加包体积。
- 清理未使用的资源:清理项目中未使用的图片、音频等资源文件,以及未使用的类和合并重复功能的类。
- 模块化设计:将App拆分成多个模块,每个模块独立编译和打包,可以根据需要动态加载或更新模块,减少主包的体积。
- 依赖管理:合理使用CocoaPods、Carthage等依赖管理工具,管理项目的第三方库依赖,避免不必要的库被包含进最终的包中。
Periphery 是一个用于识别 Swift 项目中未使用代码的工具。Periphery 能够清除的无用代码种类有未使用的函数和方法,变量和常量,类或结构体,协议,枚举,全局和静态变量,导入语句和扩展。
需要注意的是,Periphery 可能会因为项目的特殊配置或动态特性(如反射、运行时类型检查等)而错过一些实际上在使用中的代码。
Periphery 不能自动清除或处理的代码有被间接引用的代码,未来可能使用的代码,跨项目共享的代码,特定构建配置下的使用,编译器特性或优化相关的代码。
Periphery 主要使用静态代码分析技术来识别 Swift 项目中未使用的代码。这种技术允许它在不实际运行代码的情况下,通过扫描代码库来查找潜在的问题,如未使用的变量、废弃的函数等。
Periphery 首先使用 xcodebuild 构建指定的 Xcode 工作区或项目,并通过 --schemes 和 --targets 选项指定要构建的方案和目标。它索引这些目标中所有文件的声明和引用,生成一个包含这些信息的图形。在图形构建完成后,Periphery 对其执行大量的变异操作,并通过分析这些变异来识别未使用的声明。这些声明可能包括类、结构体、协议、函数、属性、构造函数、枚举、类型别名或关联类型等。Periphery 能够执行更高级的分析,例如识别协议函数中未使用的参数,但这需要在所有实现中也未使用时才会报告。类似地,重写函数的参数也只有在基函数和所有重写函数中也未使用时才会被报告为未使用。允许用户通过 YAML 配置文件来自定义排除规则,以避免误报。用户可以根据项目的需求,设置特定的排除路径或模式。可以与各种 CI/CD 工具集成,如 GitHub Actions、Jenkins 和 GitLab CI/CD,实现持续集成中的静态代码分析。通过自动运行代码扫描,Periphery 可以帮助团队在每次提交或拉取请求时发现和解决潜在的问题。Periphery 提供了两种扫描命令:scan 和 scan-syntax。scan-syntax 命令只执行语法分析,因此速度更快,但可能无法提供与 scan 命令相同水平的准确性。用户可以根据项目的具体需求选择合适的命令。
Swift 代码静态分析的开源项目还有 SwiftLint 和 SourceKitten。
接下来具体说下运行时无用类检测方案。
静态检测,通过分析Mach-O文件中的__DATA __objc_classlist和__DATA __objc_classrefs段,获取未使用的类信息。但存在无法检测反射调用类及方法的缺点。
动态检测的方法。在Objective-C(OC)中,每个类结构体内部都含有一个名为isa的指针,这个指针非常关键,因为它指向了该类对应的元类(meta-class)。元类本身也是一个类,用于存储类方法的实现等信息。
通过对元类(meta-class)的结构体进行深入分析,我们可以找到class_rw_t这样一个结构体,它是元类内部结构的一部分。在class_rw_t中,存在一个flag标志位,这个标志位用于记录类的各种状态信息。
通过检查这个flag标志位,我们可以进行一系列的计算或判断,从而得知当前类在运行时(runtime)环境中是否已经被初始化过。这种机制是Objective-C运行时系统的一个重要特性,它允许开发者在运行时动态地获取类的信息,包括类的初始化状态等。
也就是通过isa指针找到元类,再分析元类中的class_rw_t结构体中的flag标志位,我们可以得知OC中某个类是否已被初始化。
// class is initialized
#define RW_INITIALIZED (1<<29)
struct objc_class : objc_object {
bool isInitialized() {
return getMeta()->data()->flags & RW_INITIALIZED;
}
};在Objective-C的运行时(runtime)机制中,类的内部结构和状态通常是由Objective-C运行时库管理的,而不是直接暴露给开发者在应用程序代码中调用的。不过,你可以通过Objective-C的runtime API来间接地获取这些信息。
关于类是否已被初始化的问题,通常不是直接通过objc_class结构体中的某个函数来判断的,因为objc_class结构体(及其元类)的细节和具体实现是私有的,并且不推荐开发者直接操作。然而,Objective-C运行时确实提供了一些工具和API来检查类的状态和行为。
为了检查一个类是否在当前应用程序的生命周期中被使用过(即“被初始化过”),开发者可能会采用一些间接的方法,而不是直接操作类结构体的内部函数。以下是一个简化的说明:
由于不能直接访问类的内部结构,开发者可能会通过其他方式来跟踪类的使用情况。例如,可以在类的初始化方法中设置一个静态标志位或计数器,以记录类是否已被初始化或实例化的次数。虽然不能直接调用objc_class结构体中的函数,但开发者可以使用Objective-C的runtime API(如objc_getClass、class_getInstanceSize等)来获取类的元信息和执行其他操作。然而,对于直接检查类是否“被初始化过”的需求,这些API可能并不直接提供所需的功能。在实际应用中,可能并不需要直接检查类是否“被初始化过”,而是可以通过检查该类的实例是否存在、类的某个特定方法是否被调用过等间接方式来判断。自定义与系统类相同的结构体并实现isInitialized()函数可能是一种模拟或抽象的方式。然而,在实际Objective-C开发中,这样的做法是不必要的,因为直接操作类的内部结构是违反封装原则且容易出错的。相反,开发者应该利用Objective-C提供的runtime API和其他设计模式来达成目标。提到通过赋值转换获取meta-class中的数据,这通常指的是利用Objective-C的runtime机制来查询类的元类信息。然而,直接“判断指定类是否在当前生命周期中是否被初始化过”并不是通过简单地查询元类数据就能实现的,因为这需要跟踪类的实例化过程,而不是仅仅查看元类的结构。
获取类结构体里面的数据
struct mock_objc_class : lazyFake_objc_object {
mock_objc_class* metaClass() {
#if __LP64__
return (mock_objc_class *)((long long)isa & ISA_MASK);
#else
return (mock_objc_class *)((long long)isa);
#endif
}
bool isInitialized() {
return metaClass()->data()->flags & RW_INITIALIZED;
}
};所有 OC 自定义类
Dl_info info;
dladdr(&_mh_execute_header, &info);
classes = objc_copyClassNamesForImage(info.dli_fname, &classCount);是否初始化
struct mock_objc_class *objectClass = (__bridge struct mock_objc_class *)cls;
BOOL isInitial = objectClass->isInitialized();最后通过无用类占比指标(无用类数量/总类数量*100%)快速识别不再被使用的模块。对于无用类占比高的模块,进行下线或迁移处理,减少组件数量。
更细粒度无用方法检测方案有:
- 结合Mach-O和LinkMap文件分析获取无用方法,但准确率低。
- 用 Swift 编写的工程代码静态分析命令行工具 smck、使用Swift3开发了个macOS的程序可以检测出objc项目中无用方法,然后一键全部清理
- LLVM插桩获得所有方法及其调用关系。通过分析调用关系,找出未被调用的方法。详见使用 LLVM
编译器优化
Xcode 14的编译器可能通过更智能的分析,识别并消除不必要的Retain和Release调用。这些调用在内存管理中是必要的,但在某些情况下,它们可能是多余的,因为对象的生命周期管理可以通过其他方式更有效地实现。在Objective-C的运行时层面,Xcode 14可能引入了更高效的内存管理策略。这些策略可能包括更快的对象引用计数更新、更智能的对象生命周期预测等,从而减少了Retain和Release操作的执行次数和开销。剥离了未使用的代码和库,包括那些与Retain和Release操作相关的部分。这种优化可以减少最终生成的二进制文件的大小。
一些配置对包体积的优化:
- Generate Debug Symbols:在Levels选项内,将Generate Debug Symbols设置为NO,这可以减小安装包体积,但需要注意,这样设置后无法在断点处停下。
- 舍弃老旧架构:舍弃不再支持的架构,如armv7,以减小安装包体积。
- 编译优化选项:在Build Settings中,将Optimization Level设置为Fastest, Smallest [-Os],这个选项会开启那些不增加代码大小的全部优化,并让可执行文件尽可能小。同时,将Strip Debug Symbols During Copy和Symbols Hidden by Default在release版本设为yes,可以去除不必要的调试符号。
- 预编译头文件:将Precompile Prefix Header设置为YES,预编译头文件可以加快编译速度,但需要注意,一旦PCH文件和引用的头文件内容发生变化,所有引用到PCH的源文件都需要重新编译。
- 仅编译当前架构:在Debug模式下,将Build Active Architecture Only设置为YES,这样只编译当前架构的版本,可以加快编译速度。但在Release模式下,需要设置为NO以确保兼容性。
- Debug Information Format:设置为DWARF,减少dSYM文件的生成,从而减少包体积。
- Enable Index-While-Building Functionality:设置为NO,关闭Xcode在编译时建立代码索引的功能,以加快编译速度。
另外
还可以使用 -why_load 链接器标志来减少 iOS 应用程序的二进制文件大小, -why_load 标志的作用:它可以帮助开发者识别最终二进制文件中包含的不必要符号。
在 iOS 开发中,链接器负责将代码、库和资源结合成一个最终的可执行文件。在此过程中,可能会有一些不必要的代码被包含进去,例如未使用的库、重复的符号或模块。这些多余的代码会导致应用程序的二进制文件增大,进而影响应用的下载速度、安装时间以及设备的存储空间。
-ObjC 标志,它通常用于强制链接所有 Objective-C 代码到最终的二进制文件中。这在某些情况下是必要的,例如使用了某些需要反射的 Objective-C 代码时,但是它也会导致未使用的代码被包含进去。通过 -why_load,开发者可以识别出哪些代码是多余的,并通过删除 -ObjC 标志来减少文件大小。
性能分析
有些开源的工具可以直接用于性能分析。
- XCTest XCTest 是 Apple 官方的单元测试框架,支持性能测试。开发者可以通过
measure方法来衡量代码块的执行时间,从而发现性能瓶颈。适合需要在单元测试中添加性能测试的场景。 - KSCrash KSCrash 是一个强大的崩溃报告框架,它不仅能够捕获崩溃信息,还能提供应用程序的性能数据,例如内存使用和 CPU 使用情况。适合需要深入了解崩溃原因并监控相关性能数据的场景。
- GT (GDT, GodEye) GodEye 是一个开源的 iOS 性能监控工具包,提供了多种监控功能,包括 FPS、内存使用、CPU 使用率、网络请求、崩溃日志等。它有一个方便的 UI,可以实时显示性能数据。适合在开发过程中嵌入应用进行实时性能监控。
- libimobiledevice libimobiledevice 是一个开源的库,提供了与 iOS 设备交互的 API,可以用来监控设备状态和性能,特别是对非越狱设备进行操作。
常用的 In-app Debug 工具有:
- Flex 是一个功能强大的 In-app Debug 工具,允许开发者在应用内实时查看和修改视图层次结构、网络请求、用户默认设置等。它还支持动态调整 UI 以及调试其他 app 内部逻辑。无需重新编译代码即可直接调试;可以修改内存中的值来观察变化。
- Chisel 是 Facebook 开发的一组 LLDB 命令集,专门用于在调试时提供更方便的操作。它能帮助开发者快速检查视图层次结构、查看控件信息等。与 Xcode LLDB 无缝集成,通过命令行调试视图、打印出布局相关信息等。
- Reveal 是一个图形化的 In-app Debug 工具,它允许开发者在运行中的应用中实时查看和编辑视图层次结构,支持 2D 和 3D 的视图展示。提供直观的 UI 调试界面,可以轻松地查看和修改视图属性;支持 iOS 和 tvOS。
- Lookin 是一个开源的 iOS 视觉调试工具,专门用于分析和检查 iOS 应用的界面结构。它提供类似于 Xcode 的 View Debugging 功能,但更加灵活和强大,尤其是在复杂 UI 布局的分析上。通过 Lookin,你可以轻松地获取 iOS 应用中的界面层级、布局信息,并进行实时的 UI 调试和调整。可以称之为开源版的 Reveal。
Bazel
介绍
Polyrepo(多仓库)在代码量不断增加,开发团队扩大后,会觉得不合适,比如配置 CI 工具的繁琐,容易出现冗余代码,构建出现问题滞后等。Monorepo 指的是将多个模块化的 package 或 library 放在一个高度模块化且可管理的单一代码仓库中。谷歌的 Blaze、Bazel,以及微软的 Lage 和 Rush 等工具都是典型的 Monorepo 工具。Bazel 是一个现代化的多语言构建和测试工具。
你可以理解为是现代化的 Make 工具,但更加强大。
Bazel 通过缓存和增量构建机制,可以有效减少重复构建时间。支持并行构建,能够利用多核处理器提高构建速度。这两个点应该就是最吸引人的地方了。
另外它还允许用户定义自己的构建规则。因此,Bazel 是很适合大型的项目,还有容器化的应用。
接下来我就详细的说下 Bazel 是怎么使用的。
Bazel 组织 iOS 工程结构的方式具有高度的模块化和可管理性。
- WORKSPACE 文件:根目录的核心文件。每个使用 Bazel 的项目都会在项目根目录中包含一个
WORKSPACE文件,这个文件定义了项目的整体环境和依赖项。它类似于项目的“入口点”,Bazel 通过它知道如何构建整个项目。 - BUILD 文件:模块的定义。在 Bazel 中,每个独立的模块(如一个应用、库、测试等)都需要一个
BUILD文件,这个文件定义了该模块的构建规则。通过BUILD文件,开发者可以指定模块的依赖项、构建方式(如编译源代码、生成静态库等),以及测试配置。 - Targets(目标):构建单元。
BUILD文件中定义的每个构建任务被称为“Target”(目标),可以是一个 iOS 应用程序、一个静态库、或单元测试等。目标可以依赖其他目标,这样可以构建出复杂的依赖图,确保模块间的依赖关系被正确处理。 - 模块化组织:模块隔离与复用。Bazel 鼓励将代码分解成多个模块,每个模块都可以独立构建和测试。这种模块化结构提高了代码的可复用性,也简化了依赖管理。
- 依赖管理:声明式依赖。Bazel 使用声明式依赖管理,即通过
BUILD文件明确指定每个模块依赖哪些其他模块。这种方式有助于避免传统 iOS 项目中常见的依赖冲突和版本管理问题。 - 跨语言支持:对于使用多种编程语言的项目,Bazel 提供了原生支持。对于 iOS 工程,Bazel 既支持 Objective-C 和 Swift 的构建,也支持与其他语言(如 C++、Java)的集成。
- 并行构建与缓存:增量构建和缓存。Bazel 的构建系统支持并行构建和缓存。它能够有效地重用已经构建的模块,避免重复构建,从而大幅缩短构建时间。
- Xcode 集成:与 Xcode 协作。虽然 Bazel 可以独立执行构建任务,但它也提供了与 Xcode 的集成,开发者可以在 Xcode 中进行代码编辑和调试,同时使用 Bazel 进行构建和测试。
WORKSPACE 文件
WORKSPACE 文件是定义项目根目录的关键文件,它告诉 Bazel 项目依赖了哪些外部库和资源,并为整个构建过程提供了基础配置。下面是一个典型的 WORKSPACE 文件的结构和示例代码:
一个典型的 WORKSPACE 文件包括以下部分:
- 加载 Bazel 提供的 iOS 相关规则集,如
rules_apple和rules_swift。 - 声明项目中使用的第三方库,通常使用
http_archive或git_repository来加载外部依赖。 - 配置目标平台、构建工具链等。
# WORKSPACE 文件的开头,定义需要加载的规则集
# 引入苹果生态系统的 Bazel 规则
load("@bazel_tools//tools/build_defs/repo:http.bzl", "http_archive")
# 加载苹果的构建规则 (rules_apple)
http_archive(
name = "build_bazel_rules_apple",
url = "https://github.com/bazelbuild/rules_apple/releases/download/1.0.0/rules_apple.1.0.0.tar.gz",
strip_prefix = "rules_apple-1.0.0",
)
# 加载 Swift 的构建规则 (rules_swift)
http_archive(
name = "build_bazel_rules_swift",
url = "https://github.com/bazelbuild/rules_swift/releases/download/0.24.0/rules_swift.0.24.0.tar.gz",
strip_prefix = "rules_swift-0.24.0",
)
# 使用 rules_apple 提供的默认设置
load("@build_bazel_rules_apple//apple:repositories.bzl", "apple_rules_dependencies")
apple_rules_dependencies()
# 使用 rules_swift 提供的默认设置
load("@build_bazel_rules_swift//swift:repositories.bzl", "swift_rules_dependencies")
swift_rules_dependencies()
# 加载 CocoaPods 规则(如果项目中使用了 CocoaPods)
http_archive(
name = "bazel_pod_rules",
url = "https://github.com/pinterest/PodToBUILD/releases/download/0.1.0/PodToBUILD.tar.gz",
strip_prefix = "PodToBUILD-0.1.0",
)
# 声明 Xcode 版本和 SDK 的目标设置(可选)
load("@build_bazel_rules_apple//apple:config.bzl", "apple_common")
apple_common.xcode_config(
name = "xcode_config",
default_ios_sdk_version = "14.5",
default_macos_sdk_version = "11.3",
default_watchos_sdk_version = "7.4",
default_tvos_sdk_version = "14.5",
)
# 声明项目中使用的第三方库(例如使用 gRPC 或其他库)
load("@bazel_tools//tools/build_defs/repo:git.bzl", "git_repository")
git_repository(
name = "com_github_grpc_grpc",
commit = "your_commit_hash",
remote = "https://github.com/grpc/grpc.git",
)
# 声明额外的外部依赖(例如 Swift Package Manager 包)
load("@build_bazel_rules_swift//swift:repositories.bzl", "swift_package")
swift_package(
name = "swift_lib_example",
repository = "https://github.com/apple/swift-argument-parser",
revision = "0.4.4",
)
# 配置 BUILD.bazel 文件所在目录中的第三方依赖
load("@bazel_pod_rules//:defs.bzl", "new_pod_repository")
new_pod_repository(
name = "AFNetworking",
url = "https://github.com/AFNetworking/AFNetworking.git",
tag = "4.0.1",
)rules_apple 和 rules_swift 是 Bazel 提供的官方规则集,用于构建 iOS 和 Swift 项目。通过 http_archive 你可以指定需要的规则集版本。http_archive 和 git_repository 用于加载第三方库或工具集成。new_pod_repository 是专门为 CocoaPods 提供的规则,用于管理 iOS 项目中的 CocoaPods 依赖。apple_common.xcode_config 用于指定 iOS SDK 版本、Xcode 版本等,可以确保项目在正确的环境下构建。
BUILD 文件
编写 iOS 程序的 BUILD 文件时,需要使用 Bazel 提供的专门规则来构建 iOS 应用、库和测试。这些规则可以帮助你定义目标、依赖项和其他构建配置。
基本概念
ios_application: 用于定义一个 iOS 应用的目标。objc_library: 用于定义一个 Objective-C 或 Swift 库。ios_unit_test和ios_ui_test: 用于定义 iOS 的单元测试和 UI 测试目标。apple_binary: 用于定义一个包含所有依赖的 iOS 可执行文件,通常与ios_application一起使用。
假设我们有一个简单的 iOS 项目,它包含一个应用和一个静态库,项目结构如下:
项目结构
my_ios_project/
├── WORKSPACE
├── BUILD
├── App/
│ ├── BUILD
│ ├── AppDelegate.swift
│ ├── ViewController.swift
│ ├── Assets.xcassets
│ └── Main.storyboard
└── Libs/
├── BUILD
├── MyLib.swift
└── MyLib.hLibs/BUILD 文件
首先,定义一个 Objective-C/Swift 库,这个库将在应用中使用:
# 用于定义一个 Objective-C 或 Swift 的库。
objc_library(
name = "MyLib", # 库目标的名称。
srcs = ["MyLib.swift"], # 源文件列表(包括 Swift 和 Objective-C 文件)。
hdrs = ["MyLib.h"], // 头文件列表(如果有 Objective-C 文件)。
visibility = ["//visibility:public"], # 公开可见,以供其他目标使用
)接下来,定义 iOS 应用目标,并指定它依赖于上面定义的库:
# 用于定义一个 iOS 应用目标。
ios_application(
name = "MyApp", # 应用目标的名称。
bundle_id = "com.example.MyApp", # 应用的唯一标识符。
families = ["iphone", "ipad"], # 目标设备类型(如 iPhone 和 iPad)。
infoplists = ["Info.plist"], # 应用的 `Info.plist` 文件。
srcs = ["AppDelegate.swift", "ViewController.swift"], # 应用的源文件列表(Swift 和 Objective-C)。
storyboards = ["Main.storyboard"],
resources = glob(["Assets.xcassets/**/*"]), # 应用的资源文件,如图像、音效等,使用 `glob` 语法可以方便地将多个资源文件包含在 `BUILD` 文件中。
deps = ["//Libs:MyLib"], # 依赖于 MyLib 库。 `deps` 参数用来定义该目标依赖的其他库或目标,Bazel 会自动处理这些依赖关系并确保它们的构建顺序正确。
)通常在项目的根目录也会有一个 BUILD 文件来聚合或定义一些全局目标,或仅作为入口文件:
# 设置包的默认可见性,这里设置为对所有目标公开可见。
package(default_visibility = ["//visibility:public"])
# 创建别名,方便从顶层访问应用目标。
alias(
name = "app",
actual = "//App:MyApp",
)Starlark 语言
Starlark 是一种由 Bazel 使用的嵌入式编程语言,用于定义构建规则和操作构建文件。它类似于 Python,专门设计用于 Bazel 的构建系统,允许用户扩展 Bazel 的功能。在 iOS 工程构建中,Starlark 主要用于编写自定义的规则、宏和函数。
Starlark 基础语法
Starlark 的语法类似 Python,包括变量、函数、条件、循环等基本结构。
变量与函数
# 定义变量
message = "Hello, Starlark!"
# 定义函数
def greet(name):
return "Hello, " + name + "!"条件与循环
# 条件语句
def is_even(x):
if x % 2 == 0:
return True
else:
return False
# 循环语句
def sum_of_evens(limit):
sum = 0
for i in range(limit):
if is_even(i):
sum += i
return sum使用 Starlark 自定义 iOS 构建
假设你想要定义一个自定义的 iOS 静态库规则,它能够简化库的定义并统一管理依赖。
项目结构
my_ios_project/
├── WORKSPACE
├── BUILD
├── app/
│ ├── BUILD
│ ├── AppDelegate.swift
│ └── ViewController.swift
└── libs/
├── BUILD
├── mylib.swift
└── lib.bzl编写 lib.bzl 文件
在 libs/ 目录下创建一个 lib.bzl 文件,定义自定义的 iOS 静态库规则。
# 这是一个宏,用于简化 `objc_library` 规则的定义。通过这种方式,你可以统一管理 ARC 选项、依赖等设置。
def ios_static_library(name, srcs, hdrs = [], deps = []):
objc_library(
name = name,
srcs = srcs,
hdrs = hdrs,
deps = deps,
copts = ["-fobjc-arc"], # 指定编译选项,如在此处启用 ARC。
)使用 lib.bzl 文件中的宏
在 libs/BUILD 文件中使用上面定义的宏来创建一个 iOS 静态库。
# 用于加载 Starlark 文件中的宏或函数。在此例中,`//libs:lib.bzl` 表示加载 `libs` 目录中的 `lib.bzl` 文件。
load("//libs:lib.bzl", "ios_static_library")
# `ios_static_library` 宏会被调用来定义一个名为 `mylib` 的 iOS 静态库。
ios_static_library(
name = "mylib",
srcs = ["mylib.swift"],
)在 app/BUILD 文件中,定义一个 iOS 应用目标,并依赖于上述的静态库:
ios_application(
name = "MyApp",
bundle_id = "com.example.MyApp",
families = ["iphone", "ipad"],
infoplists = ["Info.plist"],
srcs = ["AppDelegate.swift", "ViewController.swift"],
deps = ["//libs:mylib"],
)自定义 iOS Framework 构建的示例
你可以使用 Starlark 编写更复杂的规则,例如为 iOS 定制一个 Framework 的构建规则:
# 这是一个 Bazel 的内置规则,用于创建 iOS Framework。自定义的 `ios_framework` 宏将静态库打包成一个 Framework,简化了应用与库之间的集成。
def ios_framework(name, srcs, hdrs = [], deps = [], bundle_id = None):
objc_library(
name = name + "_lib",
srcs = srcs,
hdrs = hdrs,
deps = deps,
)
apple_framework(
name = name,
bundle_id = bundle_id,
infoplists = ["Info.plist"],
deps = [":" + name + "_lib"],
)运行
在终端中运行以下命令来构建 iOS 应用。
构建应用
bazel build //App:MyApp运行应用
bazel run //App:MyApp测试应用
bazel test //App:MyAppTestsrules_xcodeproj 生成 Xcode 工程
rules_xcodeproj 是一个用于生成 Xcode 工程文件 (.xcodeproj) 的 Bazel 插件。它允许你在使用 Bazel 构建系统的同时,仍然能够使用 Xcode 进行开发和调试。它目前支持两种主要的构建模式:BwB (Build with Bazel) 和 **BwX (Build with Xcode)**。
BwB 模式是将 Bazel 作为主要的构建工具,Xcode 项目仅用于 IDE 支持,而实际的构建过程完全由 Bazel 管理。BwX 模式官方后续支持会变弱,不建议使用。
首先,在你的 WORKSPACE 文件中添加 rules_xcodeproj 规则的依赖项。
load("@bazel_tools//tools/build_defs/repo:http.bzl", "http_archive")
http_archive(
name = "build_bazel_rules_xcodeproj",
sha256 = "<SHA256>",
url = "https://github.com/buildbuddy-io/rules_xcodeproj/releases/download/<version>/rules_xcodeproj-<version>.tar.gz",
)
load("@build_bazel_rules_xcodeproj//:workspace_setup.bzl", "rules_xcodeproj_workspace_setup")
rules_xcodeproj_workspace_setup()你需要替换 <SHA256> 和 <version> 为相应的值,可以从 rules_xcodeproj 的发布页面 获取。
在项目的 BUILD.bazel 文件中,使用 xcodeproj 规则生成 .xcodeproj 文件。例如:
load("@build_bazel_rules_xcodeproj//:defs.bzl", "xcodeproj")
xcodeproj(
name = "MyApp_xcodeproj", # 定义生成的 `.xcodeproj` 的目标名称。
project_name = "MyApp", # 定义 Xcode 工程的名称。
targets = ["//app:MyApp"], # 指定 Bazel 中需要包含在 Xcode 工程中的目标。
)在命令行中,运行以下命令生成 Xcode 工程文件:
bazel run //:MyApp_xcodeproj这将生成一个名为 MyApp.xcodeproj 的文件,位于你运行命令的目录中。你可以用 Xcode 打开这个工程文件,并在 Xcode 中调试和开发你的应用。
rules_xcodeproj 提供了多种配置选项,你可以根据需要进行自定义。例如,可以配置生成的 Xcode 工程中的编译设置、构建配置等。以下是一些常用的配置:
xcodeproj(
name = "MyApp_xcodeproj",
project_name = "MyApp",
targets = ["//app:MyApp"],
build_settings = {
"SWIFT_VERSION": "5.0",
"CODE_SIGN_IDENTITY": "",
}, # 指定 Xcode 工程的编译设置,例如 Swift 版本、代码签名等。
extra_generated_files = ["//path/to/resource"], #指定额外的生成文件,可能包括资源文件等。
)Build with Proxy 模式
rules_xcodeproj 新推出的 Build with Proxy 模式,是一种新的构建模式。在 “Build with Proxy” 模式下,Bazel 通过 XCBBuildServiceProxy 完全接管了整个构建过程。Xcode 在这个模式下只作为一个前端界面,所有的构建逻辑和执行都由 Bazel 来完成。在 “Build with Bazel” 模式下,Xcode 依然是主导构建过程的工具,但它在构建的关键步骤(如编译和链接)上调用 Bazel 来完成实际的工作。Xcode 会生成编译任务并将其委托给 Bazel,同时保持对构建过程的部分控制权。
流程是,当开发者在 Xcode 中触发构建时,XCBBuildServiceProxy 拦截 Xcode 的构建请求。构建请求被重定向到 Bazel,由 Bazel 完全控制构建过程,包括依赖管理、编译、链接等。构建结果通过 XCBBuildServiceProxy 返回给 Xcode,Xcode 仅作为显示界面。
Bazel 完全控制构建过程,提供更高效的构建性能和更一致的结果。由于 Xcode 不再控制构建过程,调试和查看构建日志可能需要适应 Bazel 的方式,还有更高的初始配置成本。
首先,你需要在 Bazel 的 WORKSPACE 文件中引入 rules_xcodeproj:
http_archive(
name = "build_bazel_rules_xcodeproj",
url = "https://github.com/buildbuddy-io/rules_xcodeproj/releases/download/{version}/release.tar.gz",
sha256 = "{sha256}",
)
load("@build_bazel_rules_xcodeproj//xcodeproj:workspace.bzl", "xcodeproj_dependencies")
xcodeproj_dependencies()接着,在你的 BUILD 文件中配置 Xcode 项目生成规则,并启用 “Build with Proxy” 模式:
load("@build_bazel_rules_xcodeproj//xcodeproj:xcodeproj.bzl", "xcodeproj")
xcodeproj(
name = "MyAppProject",
targets = ["//App:MyApp"],
build_mode = "build_with_proxy", # 启用 "Build with Proxy" 模式
minimum_xcode_version = "14.0",
# 其他配置...
)生成 Xcode 项目文件:
bazel run //:MyAppProject生成的 .xcodeproj 文件将会配置为使用 Bazel 进行构建。
XCBBuildServiceProxy 是核心代理组件,它通过拦截 Xcode 的构建请求并将其转发给 Bazel 进行处理。在 “Build with Proxy” 模式下,Xcode 的构建流程大致如下:
# 当你在 Xcode 中点击“构建”时,Xcode 会调用 XCBBuildServiceProxy。
# XCBBuildServiceProxy 会将构建请求转发给 Bazel。
bazel build //App:MyApp
# Bazel 处理所有构建任务,包括编译、链接等。
# 构建完成后,Bazel 将结果返回给 XCBBuildServiceProxy。
# XCBBuildServiceProxy 将结果反馈给 Xcode,Xcode 显示构建输出。为了确保 Xcode 在构建时使用 Bazel,你需要配置项目的 Scheme。在生成的 .xcodeproj 文件中,确保构建 Scheme 设置为使用 XCBBuildServiceProxy 调用 Bazel。
生成 IPA 包的过程
当你运行 bazel build //App:MyApp 这条命令时,Bazel 会从指定的目标 //App:MyApp 开始,递归解析其依赖树,执行构建过程,最终生成一个 IPA 文件。
//App:MyApp 是一个 Bazel 目标,它指向一个定义在 App/BUILD.bazel 文件中的构建规则。Bazel 首先会解析这个目标并确定其直接依赖项。
假设在 App/BUILD.bazel 文件中定义了一个 ios_application 规则:
ios_application(
name = "MyApp",
bundle_id = "com.example.myapp",
families = ["iphone", "ipad"],
infoplists = ["Info.plist"],
entitlements = "MyApp.entitlements",
provisioning_profile = "//:MyAppProfile",
app_icon = "AppIcon",
launch_images = ["LaunchImage"],
deps = [
"//App/Core:core_lib",
"//App/UI:ui_lib",
],
)在这个例子中,MyApp 依赖于两个库 core_lib 和 ui_lib。
Bazel 会递归地解析 deps 字段中的依赖项,从而构建整个依赖树。在上面的例子中,Bazel 会进一步解析 //App/Core:core_lib 和 //App/UI:ui_lib 的 BUILD.bazel 文件。
假设 core_lib 和 ui_lib 是通过 objc_library 规则定义的:
# App/Core/BUILD.bazel
objc_library(
name = "core_lib",
srcs = ["CoreLib.m"],
hdrs = ["CoreLib.h"],
deps = [
"//third_party/some_lib:some_lib",
],
)# App/UI/BUILD.bazel
objc_library(
name = "ui_lib",
srcs = ["UILib.m"],
hdrs = ["UILib.h"],
deps = [
"//App/Core:core_lib",
],
)在这里,ui_lib 依赖于 core_lib,而 core_lib 依赖于一个第三方库 some_lib。
在解析完依赖树后,Bazel 开始实际的构建过程。这包括编译源文件、链接目标文件、处理资源文件,并最终打包为一个 IPA 文件。
Bazel 会首先编译 objc_library 目标。比如,将 CoreLib.m 和 UILib.m 文件编译为 .o 对象文件,并处理相应的头文件。之后,Bazel 将链接这些编译后的对象文件,生成静态库或可执行文件。Bazel 将所有编译结果(如可执行文件、静态库)、资源文件(如 Info.plist、图标)打包为一个 .app 目录。最后,Bazel 使用 ios_application 规则的配置,将 .app 目录压缩并签名为一个 IPA 文件。
Bazel 通过其强大的缓存和增量构建机制,只重新构建那些发生变化的目标。例如,如果只修改了 UILib.m 文件,那么 Bazel 只会重新编译 ui_lib 相关的目标,而不需要重新构建整个应用。
生成的 IPA 文件通常会保存在 bazel-bin 目录中,路径类似于 bazel-bin/App/MyApp.ipa。
依赖分析
Bazel 的依赖分析(dependency analysis)是其构建系统中关键的一部分,用于决定哪些文件或目标需要重新构建,以及哪些可以重用之前的构建结果。这一过程高度依赖于 Bazel 的增量构建和缓存机制。
Bazel 依赖分析的核心步骤
- 目标(Target)定义与依赖图:Bazel 使用
BUILD文件定义构建目标(如库、应用、测试等)以及这些目标之间的依赖关系。这些依赖关系形成了一个有向无环图(DAG),用于描述项目的依赖结构。 - 文件和目标的输入输出(Input/Output)追踪:Bazel 追踪每个目标的输入(源文件、依赖项)和输出(编译后的二进制文件、对象文件等)。任何影响输入的更改都会触发相应目标的重新构建。
- 哈希校验与缓存:Bazel 对每个目标的输入文件进行哈希校验(如 MD5 或 SHA-256),并将其存储在缓存中。如果同一目标的输入哈希值未发生变化,则 Bazel 直接使用缓存中的构建结果,而不需要重新构建。
- 增量构建:当 Bazel 发现输入文件发生了变化,它会自动标记该目标以及依赖于该目标的所有下游目标为“脏”(dirty),这些目标将在下一次构建时重新编译。
- 依赖分析的递归性:Bazel 的依赖分析是递归进行的。如果一个目标的依赖发生变化,Bazel 将递归地检查其所有上游目标是否需要重建。
以下是一个简单的 Bazel 项目结构示例,展示了 Bazel 的依赖分析过程:
项目结构
my_project/
├── WORKSPACE
├── BUILD
├── main/
│ ├── BUILD
│ ├── main.m
│ └── AppDelegate.m
└── libs/
├── BUILD
├── libA.m
├── libA.h
├── libB.m
└── libB.h项目根目录的 BUILD 文件:
# 根目录下的 BUILD 文件
ios_application(
name = "MyApp",
srcs = ["main/main.m", "main/AppDelegate.m"],
deps = [
"//libs:libA",
"//libs:libB",
],
)libs/ 目录的 BUILD 文件:
# libs 目录下的 BUILD 文件
objc_library(
name = "libA",
srcs = ["libA.m"],
hdrs = ["libA.h"],
)
objc_library(
name = "libB",
srcs = ["libB.m"],
hdrs = ["libB.h"],
deps = [":libA"], # libB 依赖于 libA
)Bazel 的依赖分析过程
- 依赖图的生成:
MyApp依赖于libA和libB,而libB又依赖于libA。Bazel 会根据这些依赖关系生成一个依赖图。 - 输入输出追踪与哈希校验:在每次构建时,Bazel 会对
libA.m、libB.m、main.m等输入文件进行哈希校验,并将结果与上次构建时的哈希值进行比较。例如,如果libA.m发生了变化,Bazel 会检测到其哈希值发生了变化,从而标记libA及依赖于它的libB和MyApp为“脏”。 - 增量构建:由于
libA.m发生了变化,Bazel 将重新构建libA,然后递归地重新构建依赖它的libB,最终重新构建MyApp。 - 缓存与重用:如果
libB.m和main.m没有变化,Bazel 可以重用它们之前的编译结果(缓存),只需要重新构建那些受影响的目标。 - 输出结果:最终,Bazel 生成一个新的
MyApp二进制文件,包含了最新的代码改动,并保证所有依赖关系都得到了正确的处理。
Bazel 使用哈希校验来精确判断哪些输入文件发生了变化。只有当输入文件的哈希值变化时,才会触发相应目标的重新构建,这样可以最大程度地重用已有的构建结果,减少不必要的编译时间。Bazel 的依赖分析是递归的,这意味着任何下游依赖的变化都会向上递归地影响依赖它的所有目标。这确保了每次构建的结果都是一致且正确的。由于 Bazel 精确地追踪了目标的依赖关系和输入输出变化,它能够有效地执行增量构建,只重新编译那些受影响的模块。
不会影响依赖分析缓存的代码改动有哪些呢?
在 Bazel 中,构建系统的性能很大程度上依赖于其增量构建和缓存机制。Bazel 使用依赖分析(dependency analysis)来决定哪些部分的代码需要重新构建,哪些部分可以使用缓存结果。
以下是一些不会影响依赖分析缓存的代码改动类型,这些改动不会导致 Bazel 重新构建依赖的目标,因为它们不会改变编译输出或依赖图:
- 注释的更改:添加、删除或修改代码中的注释不会影响构建输出,因为注释不参与代码编译。
- 代码格式化:仅涉及代码格式(如缩进、空格、换行)的改动不会影响构建结果,格式化不会改变编译后的二进制文件。
- 无实际影响的变量命名更改:在局部范围内(如函数内部)修改变量名称(而不影响函数签名)不会影响依赖分析缓存。
- 无效或未使用代码的添加:添加从未使用的代码(如未调用的函数)在某些情况下不会触发 Bazel 的重构建,特别是在这些代码片段与已构建目标无关时。
- 函数内部的逻辑更改:在某些情况下,对函数内部进行的改动可能不会影响其他模块的构建,具体取决于目标间的依赖关系和可见性(例如,私有函数内部的更改)。
以下是一个具体的代码示例,展示了不会影响 Bazel 依赖分析缓存的几种改动:
# 示例 BUILD 文件
# 定义一个简单的 iOS 应用程序目标
ios_application(
name = "MyApp",
srcs = ["main.m", "AppDelegate.m"],
deps = [":MyLibrary"],
)
objc_library(
name = "MyLibrary",
srcs = ["MyLibrary.m"],
hdrs = ["MyLibrary.h"],
)假设我们有以下 Objective-C 代码:
// MyLibrary.m
#import "MyLibrary.h"
// 1. 注释的改动
// 添加一些注释,不会影响 Bazel 的依赖分析缓存
// 例如:以下注释不会触发重新构建
// This is a utility function
@implementation MyLibrary
// 2. 变量名更改(局部范围)。在函数内部修改变量名称不会影响其他目标或模块的编译结果,只要变量名的改变不影响接口或其他模块的依赖。
- (void)performTask {
int localVar = 5; // 如果将 localVar 改为 anotherVar,这不会触发重新构建
NSLog(@"Task performed");
}
// 3. 代码格式改动。如添加空行、调整缩进或更改代码对齐方式等纯粹的格式改动,不会改变源代码的语义,因此不会触发重新编译。
- (void)doSomething {
int a = 10;
int b = 20; // 对齐方式或空格的改变不会触发重新构建
NSLog(@"Sum: %d", a + b);
}
// 4. 添加未使用的代码。如果添加的代码从未被调用或引用,Bazel 可能不会重新构建该模块,尤其是在该代码片段没有影响编译输出时。
- (void)unusedFunction {
NSLog(@"This function is never called.");
}
@end在 Bazel 的构建过程中,操作图(Action Graph)是一个关键的概念,它定义了构建任务之间的依赖关系,并确保这些任务能够按照正确的顺序并行执行。Baziel 使用操作图来确定哪些任务可以并行执行,哪些任务需要依赖其他任务的结果。
操作图是一个有向无环图(DAG),其中每个节点代表一个操作(Action),每个边代表操作之间的依赖关系。操作可能包括编译源文件、链接对象文件、打包资源文件等。
操作图中的节点和边的关系如下:
- 节点(Action):一个构建任务,如编译、链接或打包。
- 边(Dependency): 表示一个操作依赖于另一个操作的输出。
Bazel 从指定的构建目标(如 bazel build //App:MyApp)开始,递归地解析 BUILD 文件中定义的目标和依赖关系,生成操作图。具体步骤如下:
- Bazel 解析
BUILD文件,找到指定目标和其依赖项。 - 每个构建规则(如
objc_library,ios_application)会生成一组操作。这些操作可能包括编译源文件、链接目标文件等。 - Bazel 将生成的操作按照依赖关系连接起来,形成操作图。
Bazel 确保操作图中的操作按正确的顺序并行运行,遵循以下原则:
- 一个操作只能在它所有的依赖操作完成后才能运行。
- Bazel 会并行执行那些没有依赖关系或者依赖已经满足的操作。
假设我们有一个简单的项目,其中包含两个库和一个应用程序。每个库都有自己的源文件和头文件,应用程序依赖于这两个库。以下是 BUILD 文件的定义:
# App/Core/BUILD.bazel
objc_library(
name = "core_lib",
srcs = ["CoreLib.m"],
hdrs = ["CoreLib.h"],
)
# App/UI/BUILD.bazel
objc_library(
name = "ui_lib",
srcs = ["UILib.m"],
hdrs = ["UILib.h"],
deps = [
"//App/Core:core_lib",
],
)
# App/BUILD.bazel
ios_application(
name = "MyApp",
bundle_id = "com.example.myapp",
families = ["iphone", "ipad"],
infoplists = ["Info.plist"],
deps = [
"//App/Core:core_lib",
"//App/UI:ui_lib",
],
)对于上述项目,Bazel 会生成如下操作图:
编译操作:
CoreLib.m -> CoreLib.o(core_lib的编译操作)UILib.m -> UILib.o(ui_lib的编译操作)
链接操作:
core_lib编译完成后,可以立即编译ui_lib,因为ui_lib依赖于core_lib。- 当
core_lib和ui_lib都编译完成后,可以将它们链接到一起,生成MyApp的可执行文件。
打包操作:
- 在所有链接操作完成后,将生成的二进制文件与资源文件(如
Info.plist)打包为.app目录,然后进一步打包为 IPA 文件。
- 在所有链接操作完成后,将生成的二进制文件与资源文件(如
在这个操作图中,CoreLib.o 和 UILib.o 的编译操作可以并行执行,因为它们没有依赖关系。链接操作则需要等待所有编译操作完成后才能执行。
Bazel 在内部使用操作图来调度这些任务。通过分析操作图,Bazel 能够确定哪些任务可以并行执行,哪些任务需要等待依赖完成,从而最大化利用多核 CPU 的能力,加速构建过程。
query指令找依赖关系
Bazel 的 query 命令是一种强大的工具,用于在 Monorepo(单体代码库)中查找和分析目标之间的依赖关系。通过 query,你可以获取关于构建目标的详细信息,包括它们的依赖关系、反向依赖、测试等。
bazel query 命令的一般语法如下:
bazel query '<expression>'<expression> 是你想要查询的表达式。Bazel 提供了一系列表达式来帮助你查找所需的信息。
以下是常见的 Bazel Query 表达式
列出工作区中所有可用的构建目标:
bazel query '//...'//... 表示从当前工作区的根目录开始递归查找所有目标。
查找某个目标的所有直接和间接依赖:
bazel query 'deps(<target>)'例如,查找 //app:main 目标的所有依赖:
bazel query 'deps(//app:main)'查找哪些目标依赖于某个特定目标(即反向依赖):
bazel query 'rdeps(<scope>, <target>)'例如,查找工作区中哪些目标依赖于 //lib:my_library:
bazel query 'rdeps(//..., //lib:my_library)'例如,列出所有的测试目标:
bazel query 'kind(test, //...)'kind(test, //...) 将查找工作区中的所有测试目标。
如果只想查找目标的直接依赖而非递归依赖,可以使用:
bazel query 'deps(<target>, 1)'例如:
bazel query 'deps(//app:main, 1)'使用 attr 过滤带有特定属性的目标。例如,查找所有带有特定标签的目标:
bazel query 'attr(tags, "my_tag", //...)'假设你有以下项目结构:
workspace/
├── app/
│ ├── BUILD
│ ├── main.swift
│ └── AppDelegate.swift
├── lib/
│ ├── BUILD
│ ├── util.swift
│ └── helper.swift
└── third_party/
├── BUILD
└── external_lib.swift在 app/BUILD 文件中,你定义了一个 ios_application 目标:
ios_application(
name = "MyApp",
bundle_id = "com.example.MyApp",
srcs = ["main.swift", "AppDelegate.swift"],
deps = ["//lib:util"],
)在 lib/BUILD 文件中定义了一个 swift_library 目标:
swift_library(
name = "util",
srcs = ["util.swift", "helper.swift"],
deps = ["//third_party:external_lib"],
)你可以运行以下命令来查找 MyApp 的所有直接和间接依赖:
bazel query 'deps(//app:MyApp)'这将输出:
//app:MyApp
//lib:util
//third_party:external_lib查找依赖于 external_lib 的所有目标
你可以使用以下命令来查找反向依赖:
bazel query 'rdeps(//..., //third_party:external_lib)'这将列出所有依赖于 external_lib 的目标,比如 //lib:util。
你还可以生成图形化的依赖关系图,使用 dot 格式输出:
bazel query 'deps(//app:MyApp)' --output graph > graph.dot然后使用 Graphviz 等工具将 graph.dot 文件转换为图形文件。
query 指令是理解和管理 Monorepo 中依赖关系的关键工具。它提供了多种强大的表达式,帮助你轻松地查找目标的依赖关系、反向依赖、过滤目标等。在大型代码库中,使用 query 可以大大简化依赖关系的管理,并且可以帮助你识别不必要的依赖或者循环依赖。
远程缓存
Bazel 的远程缓存功能允许你在不同的开发环境、构建机器或 CI 系统之间共享构建产物。这可以显著加快构建速度,因为已经构建好的产物可以被重复使用,而不需要重新编译。
Bazel 的远程缓存功能可以将构建产物(如编译后的二进制文件、对象文件等)存储在一个远程存储系统中。当你在不同环境或机器上构建同一个项目时,Bazel 会检查远程缓存,并下载已存在的构建产物,而不必重新构建。
Bazel 支持多种远程缓存后端,包括:
- HTTP/HTTPS 服务器:可以使用支持 HTTP 的远程服务器作为缓存。
- 云存储:如 Google Cloud Storage (GCS) 或 Amazon S3。
- gRPC 缓存服务:可以通过 gRPC 接口进行缓存和检索。
在你的项目中,可以通过 ~/.bazelrc 文件或项目级别的 .bazelrc 文件来配置远程缓存。以下是如何配置不同类型远程缓存的示例。
配置 HTTP 远程缓存
build --remote_cache=http://my-cache-server.com/cache/如果你使用 Google Cloud Storage (GCS) 作为远程缓存,你可以这样配置:
build --remote_cache=grpc://gcs.example.com/bucket-name
build --google_credentials=/path/to/credentials.json在这个例子中,grpc://gcs.example.com/bucket-name 是 GCS 的地址,/path/to/credentials.json 是你的 GCS 凭证文件。
配置 gRPC 远程缓存
build --remote_cache=grpc://my-grpc-cache-server.com你可以使用 gRPC 缓存服务器,如 BuildBarn 或 BuildGrid 来搭建自己的 gRPC 远程缓存服务。
有些远程缓存服务需要身份认证,如 GCS 或 Amazon S3。对于 GCS,你可以配置 google_credentials 选项,或者使用 gcloud auth 命令登录:
gcloud auth application-default login对于需要 AWS 认证的服务,你可以配置 AWS CLI,然后通过环境变量传递认证信息:
export AWS_ACCESS_KEY_ID="your-access-key-id"
export AWS_SECRET_ACCESS_KEY="your-secret-access-key"配置完成后,Bazel 会自动使用远程缓存。在运行构建命令时,如:
bazel build //App:MyAppBazel 会:
- 首先检查远程缓存,是否有匹配当前源代码和构建配置的缓存。
- 如果找到匹配的缓存,直接下载使用,而不重新编译。
- 如果没有找到匹配的缓存,正常编译并将结果上传到远程缓存,以便下次使用。
注意远程缓存和远程执行是不同的概念。远程缓存仅共享构建产物,而远程执行允许你在远程机器上执行整个构建过程。你可以根据需要选择合适的方案。
以下是一个项目级别的 .bazelrc 文件示例,它配置了远程缓存到一个 HTTP 服务器:
# .bazelrc
build --remote_cache=http://cache.example.com/cache/
build --disk_cache=/path/to/local/cache
build --google_default_credentials远程执行配置
Bazel 的远程执行功能允许你在远程服务器或集群上分布式执行构建任务,而不是在本地机器上执行。这种能力特别适用于大规模的项目,可以显著缩短构建时间,因为它利用了多台机器的计算资源。
远程执行让 Bazel 在远程执行环境中运行构建任务,例如编译、链接、测试等。Bazel 将构建任务分发到一个或多个远程执行节点,这些节点并行处理任务并将结果返回给本地 Bazel 客户端。
一个典型的远程执行环境由以下组件组成:
- 远程执行服务器:处理来自 Bazel 的任务,并将它们分发给执行节点。
- 远程工作节点:这些节点执行实际的构建任务。
- Remote Cache(远程缓存):存储构建产物以便重复使用,避免重新执行相同任务。
要启用 Bazel 的远程执行功能,你需要配置 Bazel 来连接远程执行服务。配置通常在 .bazelrc 文件中完成。
假设你有一个远程执行服务器,它的地址是 remotebuild.example.com。你可以通过以下配置启用远程执行:
# .bazelrc
build --remote_executor=grpc://remotebuild.example.com:443
build --remote_cache=grpc://remotebuild.example.com:443
build --remote_timeout=300
build --spawn_strategy=remote
build --strategy=Javac=remote
build --strategy=CppCompile=remote
build --strategy=Objc=remote--remote_executor:指定远程执行服务器的地址。--remote_cache:配置远程缓存的地址,这里可以和远程执行服务器一致。--remote_timeout:设置远程执行的超时时间。--spawn_strategy=remote:告诉 Bazel 使用远程策略执行所有构建任务。--strategy=Javac=remote等:为特定类型的任务指定使用远程执行。
如果远程执行服务器需要身份验证,你可能需要配置凭据。对于 Google Cloud Remote Build Execution (RBE) 服务,典型的配置如下:
build --google_credentials=/path/to/credentials.json使用 gcloud 工具登录:
gcloud auth application-default login设置远程执行服务(如 BuildFarm、BuildGrid 或 Google 的 Remote Build Execution (RBE))通常涉及以下步骤:
- 安装和配置 Remote Execution Server:这包括配置服务器的计算资源、执行策略等。
- 配置 Remote Workers:确保工作节点能够连接到服务器,并具备执行构建任务所需的环境和依赖。
- 配置 Remote Cache:搭建和配置远程缓存,以便存储和共享构建产物。
配置完成后,你可以运行 Bazel 命令进行远程执行,例如:
bazel build //App:MyApp在这个过程中,Bazel 会:
- 将构建请求发送到远程执行服务器。
- 服务器将任务分发到远程工作节点,并行执行。
- 远程节点完成任务后,将结果和构建产物返回到本地。
- 本地 Bazel 客户端将最终产物(如可执行文件或 IPA 文件)生成。
使用远程执行的好处
- 通过分布式构建,可以显著缩短构建时间。
- 充分利用远程集群的计算资源,而不是依赖本地机器的性能。
- 确保所有开发人员、CI/CD 系统在相同的环境中执行构建,减少“在我机器上正常”的问题。
假设你有一个项目 App,其中包括一个 BUILD 文件。以下是如何在远程执行环境中构建这个项目的完整配置。
.bazelrc 文件:
build --remote_executor=grpc://remotebuild.example.com:443
build --remote_cache=grpc://remotebuild.example.com:443
build --google_credentials=/path/to/credentials.json
build --spawn_strategy=remote
build --strategy=CppCompile=remote
build --strategy=Javac=remote
build --strategy=Objc=remote然后你可以执行以下命令:
bazel build //App:MyApp自定义构建规则
Bazel 的可扩展性是其强大功能之一,它允许开发者为尚未支持的编程语言或构建工具创建自定义的构建规则。通过编写自定义规则,你可以让 Bazel 识别、编译、链接特定语言的代码,并将它们集成到现有的 Bazel 构建系统中。
在自定义规则中,你可以指定输入、输出、依赖关系以及构建过程中的具体操作。
一个自定义的 Bazel 构建规则通常包括以下部分:
- 规则定义:描述构建过程的逻辑和依赖关系。
- 构建步骤:实际执行的命令,比如编译或链接操作。
- 规则调用:在
BUILD文件中调用自定义规则来应用于实际项目。
假设我们要为一个尚未被官方支持的编程语言 MyLang 创建一个简单的构建规则,该规则能够将 .mylang 源文件编译为可执行文件。
首先,在项目的根目录下创建一个 mylang_rules.bzl 文件,用于定义 MyLang 的构建规则。
# mylang_rules.bzl
def _mylang_binary_impl(ctx):
# 输入文件
source = ctx.file.src
# 输出文件 (可执行文件)
output = ctx.actions.declare_file(ctx.label.name)
# 编译命令
ctx.actions.run(
inputs=[source],
outputs=[output],
arguments=[source.path, "-o", output.path],
executable="path/to/mylang_compiler",
)
return DefaultInfo(
executable=output,
)
# 定义 mylang_binary 规则
mylang_binary = rule(
implementation=_mylang_binary_impl,
attrs={
"src": attr.label(allow_single_file=True), # 单个源文件
},
executable=True, # 生成可执行文件
)_mylang_binary_impl 实现了 mylang_binary 规则的逻辑,它使用 Bazel 的 ctx.actions.run 来定义编译过程。mylang_binary定义了一个新的构建规则,允许我们在 BUILD 文件中使用 mylang_binary 规则来处理 MyLang 源文件。
在你的项目中,使用自定义的 mylang_binary 规则。比如,在 my_project/BUILD 文件中:
# my_project/BUILD
load("//:mylang_rules.bzl", "mylang_binary")
mylang_binary(
name = "my_program",
src = "main.mylang",
)这个 BUILD 文件表示使用 mylang_binary 规则编译 main.mylang 文件,并生成一个名为 my_program 的可执行文件。
你可以通过 Bazel 构建这个项目:
bazel build //my_project:my_program这将使用 MyLang 编译器将 main.mylang 编译为 my_program 可执行文件。
自定义规则的功能可以进一步扩展。例如,你可以添加支持多个源文件、库依赖、资源文件等。如果你希望 mylang_binary 支持多个源文件,可以修改规则定义:
# mylang_rules.bzl
def _mylang_binary_impl(ctx):
sources = ctx.files.srcs
output = ctx.actions.declare_file(ctx.label.name)
# 假设 mylang_compiler 能够接受多个源文件
args = [source.path for source in sources] + ["-o", output.path]
ctx.actions.run(
inputs=sources,
outputs=[output],
arguments=args,
executable="path/to/mylang_compiler",
)
return DefaultInfo(
executable=output,
)
mylang_binary = rule(
implementation=_mylang_binary_impl,
attrs={
"srcs": attr.label_list(allow_files=True), # 支持多个源文件
},
executable=True,
)在 BUILD 文件中:
# my_project/BUILD
mylang_binary(
name = "my_program",
srcs = ["main.mylang", "utils.mylang"],
)通过创建自定义规则,你可以将 MyLang 与 Bazel 的其他功能(如远程缓存、远程执行、增量构建等)集成在一起。你还可以通过将规则打包为 Bazel 模块,供其他项目复用。